
¹ Holon Institute of Technology · ² Afeka College of Engineering
Corresponding author: Dr. Yehudit Aperstein, Afeka College of Engineering (apersteiny@afeka.ac.il).
Generative AI makes answers cheap and understanding scarce: students can now produce fluent work without the thinking a degree should develop. The competency that matters is no longer solving a problem unaided but working well with a fallible machine. Yet this ability is rarely assessed on its own; where measured, it collapses into a single "prompting" score that cannot say why AI use succeeded or failed. We propose CoRe-3 (Co-Reasoning), a competency model that factors productive AI use into three assessable skills, abbreviated FJS: Framing (structuring the task before invoking AI), Judging (evaluating the output), and Steering (redirecting the model). Its distinguishing claim is the separation of pre-generation Framing from post-generation Steering, with Judging as the gate between. We ground the skills in metacognition and self-regulated learning theory, state five testable propositions, and instantiate them in an open platform that scores each skill independently. Over simulated learners of controlled competence, graded by a different model from a different vendor and with the free-text skills scored blind to the intended competence, the three grades dissociate: each tracks its own manipulated skill while staying flat in the others, and correlate only when one ability is shared across all three, the convergent-and-discriminant signature of a valid measure. We release the instrument, the data, and a runnable human-rater protocol, positioning this as the construct-separability stage of a validity program whose human-agreement and efficacy stages are specified and ready to run.
Keywords: generative AI; AI literacy; competency assessment; metacognition; self-regulated learning; higher education
Most tools bringing generative AI into higher education optimize for the wrong variable. They shorten the path from question to answer, when the answer was never the point of a university education. The cognitive work of specifying a problem, evaluating a candidate solution, and improving it is where learning happens; when that work is delegated wholesale to a machine, the learner walks away with a correct artifact and an unchanged mind. The educational opportunity of generative AI is therefore not to deliver answers faster, but to make the reasoning around them visible, practiced, and assessable.
Recent evidence makes the stakes concrete. Frequent, uncritical AI use correlates with lower critical-thinking performance, an effect mediated by cognitive offloading and most pronounced in younger users (Gerlich, 2025). Controlled studies of AI-assisted writing report "metacognitive laziness," in which learners bypass the self-regulatory processes of diagnosing, evaluating, and revising (Fan et al., 2025), and neurophysiological work describes an accumulation of "cognitive debt" when an assistant carries the reasoning load (Kosmyna et al., 2025).
At the same time, field studies of professional AI use show that the benefit of AI is sharply conditional on the user's skill in directing it: assistance helps inside a model's competence frontier and harms outside it (Dell'Acqua et al., 2023), and the most effective users adopt an iterative, critical "push-back-and-validate" mode rather than wholesale delegation (Randazzo et al., 2025). Meta-analytic evidence underscores the stakes: human-AI teams frequently underperform the better of the human or the AI alone (Vaccaro et al., 2024), which makes the human's skill in directing the system, not mere access to it, the decisive variable. Direct behavioral evidence sharpens the point: across 16,851 real student-ChatGPT interactions from a university course (McNichols et al., 2025), students' moves are dominated by framing-type queries, while explicit verification of the AI's output (about 4% of interactions) and corrective editing (about 2.5%) are rare. This is the very under-judging and under-steering a competency model must target.
These findings share a structure. The difference between productive and counterproductive AI use is not access to AI; it is a competency that some learners exercise and others do not. This echoes the long-standing distinction between the effects obtained with a technology during use and the cognitive residue left of it, which depends on the learner's mindful engagement in the partnership (Salomon et al., 1991). If that competency can be named and decomposed, it can be taught and assessed. Current AI-literacy assessment can often tell us that a learner's AI use is unproductive but not why: whether they specified the task badly, failed to detect the flaws in the output, or knew the flaws but could not correct them. These are different failures with different remedies, and a single "prompting" score conflates them.
This trajectory is not transient, and that is what raises the stakes for assessment. As models absorb more of the execution, the human contribution concentrates in the operations a system cannot perform on its own behalf: specifying which problem is worth solving, judging whether a fluent output is right, and redirecting the model when it is not. Field evidence that AI's value is conditional on the user's skill (Dell'Acqua et al., 2023; Vaccaro et al., 2024) implies this conditioning tightens as systems improve, so the durable, assessable skill shifts from executing a task to framing, judging, and steering it (Acar, 2023; Denny et al., 2024; see Figure 1). An assessment that still measures unaided execution therefore measures a shrinking part of what competent work will require.
Figure 1 (schematic). As models absorb more of the execution, the part of a task a competent person must still own shifts from doing the work toward framing, judging, and steering it; the axes are conceptual, not quantitative. CoRe-3 is a decomposition and assessment of that shifting contribution.
We propose CoRe-3 (Co-Reasoning), a competency model that decomposes productive work with generative AI into three distinct skills, each independently assessable and collectively abbreviated FJS:
Contributions. This paper makes the following contributions, spanning a theoretical framework and its novelty positioning (1-4), a feasibility demonstration (5), and a released artifact and protocol (6):
Following the argument-based validity tradition (Kane, 2013; Messick, 1995), instrument development proceeds in stages: a measure must first separate the constructs it claims to measure before human-agreement and outcome evidence are warranted. This paper delivers that prerequisite stage, construct separability and automated measurability, with a released, runnable protocol for the human-agreement stage that follows (Section 9.3).
Existing instruments for assessing how university students work with AI are not wrong so much as under-resolved. Knowledge-oriented frameworks such as Long and Magerko (2020) and the UNESCO (2024) student competency framework define AI literacy chiefly as understanding AI systems: what AI is, what it can and cannot do, how it works, and how it should be governed. These are necessary, but they say little about the performance of working with a model on a task. Prompt-literacy and generative-AI-literacy models (Lo, 2023; Annapureddy et al., 2024) move closer to performance, but they bundle task specification and iterative refinement into a single "prompting" competency and treat evaluation of the output as a downstream check rather than a co-equal skill.
The cost of this coarse resolution is diagnostic. When a learner's AI use produces a poor result, a single prompting score cannot tell an instructor which cognitive operation failed: did the learner specify the task badly, so that the model solved the wrong problem; did they fail to detect the flaws in an otherwise plausible output; or did they see the flaws but issue corrections too vague to fix them? These are three different failures with three different remedies (teaching problem specification, teaching critical evaluation, and teaching corrective communication), and an instrument that cannot separate them cannot guide instruction. Integrative reviews of AI literacy after generative AI confirm that the field still lacks a scheme isolating distinct, independently-assessable reasoning competencies (Gu & Ericson, 2025), even as syntheses document generative AI's mixed effects on critical and creative thinking (Li et al., 2026). A diagnostic competency model must therefore decompose the human-AI loop into the distinct operations that can each break, and must show that those operations are in fact separable in learners. That is the gap CoRe-3 addresses.
The three FJS skills are not an arbitrary list; they instantiate a well-understood cognitive architecture. Nelson and Narens (1990) describe metacognition as a two-level system: an object level (cognition itself) and a meta level (a dynamic model of the object level), linked by monitoring (information flowing from object to meta) and control (commands flowing from meta to object). In CoRe-3, the learner's meta level supervises an object level that is external, the AI's generative process, rather than the learner's own cognition. This is a deliberate extension of the Nelson-Narens architecture from intrapersonal monitoring to what we term exo-directed monitoring and control, and it is the framework's central theoretical move: the same metacognitive machinery is turned outward onto a fallible cognitive artifact. This extension is non-trivial. Exo-directed monitoring adds an epistemic-vigilance burden that self-monitoring does not have: the learner must judge the reliability of a source whose competence differs from, and is hidden from, their own. This is exactly why Judging is bounded by domain knowledge (Proposition P4). With that point made, the mapping is direct:
The Judge→Steer cycle is therefore a monitor→control loop seeded by a task definition. This is the structural spine of the framework and the reason the three skills cohere rather than coexist by stipulation (Figure 2).

Figure 2. The CoRe-3 loop. An upstream task definition (Framing, a self-regulated-learning forethought activity) sets the standards against which a metacognitive monitor-control cycle (Judging then Steering) supervises a fallible AI at the object level. Judging is the monitor's read-out; Steering is the controller's write.
Existing frameworks treat "use the AI well" as one skill or, at most, pair "prompt" with "evaluate." CoRe-3's distinctive move is to separate two operations that prior models fuse: the pre-generation skill of structuring the task (Framing) and the post-generation skill of correcting the output (Steering). These are different cognitive acts at different points in time, with different error modes and different instructional remedies. A learner can frame impeccably and steer poorly (detect a flaw but issue a vague correction), or steer fluently atop a malformed task (drive the AI energetically toward the wrong target). Collapsing both into "prompting" hides exactly the distinctions an educator needs.
Because Judging and Steering both occur after generation and in a tight loop, their boundary needs stating precisely. Judging is assessment; Steering is action. Judging produces a representation of what is wrong with the current output, an internal or articulated list of detected flaws, gaps, and risks, and a calibrated sense of how much to trust the output. It is evaluative and its output is a diagnosis. Steering consumes that diagnosis and produces a corrective instruction aimed at changing the next output: it is generative and directive, and its quality depends on prioritization (addressing the most critical flaw first), specificity (an actionable command rather than "improve this"), and effectiveness (whether the output actually converges). In the monitor-control terms of Section 3.1, Judging is the monitor's read-out and Steering is the controller's write. The two dissociate because the competencies differ: a learner may diagnose accurately yet communicate the fix poorly (good Judging, weak Steering), or issue fluent, confident commands that target the wrong thing because the diagnosis was wrong (weak Judging propagating into misdirected Steering, the failure mode Proposition P2 predicts). This last point also reconciles an apparent tension: P2 (Judging bounds Steering) implies the two grades will be positively correlated in the aggregate, while P3 claims they dissociate. Both hold. P2 is a ceiling relation (Steering cannot exceed the quality its Judging permits), which induces correlation without identity; P3 is the claim that the off-diagonal is well below the reliability ceiling, so the skills are not interchangeable. We therefore test dissociation pairwise and report whether each skill's grade responds to its own manipulated competence while remaining comparatively flat in the others, rather than relying on a single global factor model.
Each skill is anchored in established theory, and the anchors are mutually consistent because they share the metacognitive backbone of Section 3.1.
Framing is the task-definition phase of self-regulated learning. In the COPES model (Winne & Hadwin, 1998), self-regulated work begins by constructing a definition of the task and the standards a product must satisfy; Zimmerman's (2000) forethought phase similarly precedes performance with goal setting and strategic planning. Framing applies this phase to a human-AI loop: the learner converts an ill-defined situation into a specified task with explicit constraints and success criteria. In Bloom's revised taxonomy (Anderson & Krathwohl, 2001), specifying an original task is a Create-level activity, and the competence to know what makes a task tractable for a given tool is metacognitive task knowledge (Flavell, 1979).
Judging is metacognitive monitoring (Nelson & Narens, 1990) directed at an external generative source. Its content is the evaluative core of critical thinking, the Delphi-consensus skills of analysis and evaluation (Facione, 1990) and the Paul and Elder (2006) intellectual standards, which supply a ready vocabulary for assessing reasoning. Because the object being judged is a communicated knowledge claim from a fluent but fallible source, the most precise anchor is epistemic vigilance (Sperber et al., 2010), which pairs source monitoring (is this source trustworthy?) with content evaluation (is this internally and externally coherent?). Barzilai and Chinn's (2018) account of apt epistemic performance adds the criteria-for-good-knowledge dimension that a learner must hold to judge well, and the human-automation literature supplies the calibration target: reliance matched to actual reliability (Lee & See, 2004), the failure of which is the over-reliance documented in AI-assisted decision-making (Bansal et al., 2021; Buçinca et al., 2021) and the broader automation-complacency it extends (Parasuraman & Manzey, 2010). That Judging is a trainable skill rather than an automatic byproduct of competence is underscored by recent evidence that metacognitive monitoring can decouple from performance in human-AI reasoning (Fernandes et al., 2024), and by recent work on whether learners can evaluate AI output quality as experts do (Nazaretsky et al., 2025).
Steering is metacognitive control (Nelson & Narens, 1990): acting on the monitoring signal to change the object-level process. Pedagogically it inverts cognitive-apprenticeship coaching and scaffolding (Collins, Brown & Newman, 1989): the learner, not the master, supplies the corrective guidance. Its quality depends on the learner monitoring the work against held standards (Sadler, 1989), and is well described by feed-forward, the "where to next" component of effective feedback (Hattie & Timperley, 2007).
The loop and its positioning. The Judge-Steer cycle is designed to push learners into the Interactive mode of the ICAP framework (interactive, constructive, active, passive; Chi & Wylie, 2014), in which knowledge is co-constructed through dialogue rather than passively received, the mode ICAP associates with the greatest learning. The framework casts the AI as a mediating cultural tool that extends the learner's zone of proximal development (Vygotsky, 1978): the learner accomplishes with the model what they could not alone, while internalizing the Framing, Judging, and Steering moves for eventual independent use.
The pedagogical stance. CoRe-3's rejection of speed-to-answer rests on the literature of productive struggle and desirable difficulties (Bjork & Bjork, 2011; Kapur, 2008): conditions that slow performance but deepen learning. The friction of specifying, evaluating, and correcting is not an obstacle to be engineered away but the very locus of learning, which is why the instructional design deliberately presents imperfect output for the learner to improve rather than a polished answer to accept.
These propositions differ in how far the present work tests them. The feasibility demonstration (Section 8) directly supports P3 (the three skills dissociate) and bears partly on P2 (the steering own-effect is bounded in a way consistent with judging gating steering). P1, P4, and P5 are stated here as falsifiable hypotheses for the validation and classroom agenda (Section 9.3), not as claims the demo establishes. Each names a concrete test: P1 fails if a strong steering intervention recovers grades after a deliberately malformed framing; P4 fails if Judging transfers across domains as readily as Framing; P5 fails if exercising the loop does not reduce the offloading signatures (for example, reduced post-task recall) documented in the cognitive-debt literature.
The constructs that compose CoRe-3 are not individually new; what is new is their separation into three parallel, independently-assessable competencies anchored in a monitor-control architecture. We make the boundary explicit against the nearest priors.
Fluency, metacognitive, and prompt-literacy frameworks. The 4D model of AI fluency (Dakan & Feller, 2025) maps Discernment onto Judging but bundles the initial specification and the iterative back-and-forth into one "Description," exactly the pre- versus post-generation operations we separate. Tankelevitch et al. (2024) analyse generative-AI use as metacognitive demands (prompting, output evaluation, workflow iteration); we share that foundation but convert a demands analysis into an assessable model with rubrics, propositions, and dissociation evidence. Prompt-literacy models such as CLEAR (Lo, 2023), including the formulate-interpret-refine decomposition of Tour and Zadorozhnyy (2025), likewise fuse task specification and refinement under "prompting" and do not grade the sub-practices as dissociable competencies. This fusion of Framing and Steering is the conflation CoRe-3 rejects, and our feasibility demonstration shows the two grades can diverge.
Literacy, metric, and mode frameworks. Knowledge-oriented AI-literacy sets (Long & Magerko, 2020; UNESCO, 2024) define literacy as understanding AI systems and contain no Framing or Steering construct, only a diffuse "critical evaluation"; CoRe-3 supplies the task-execution competencies they leave implicit. Metric schemes for human-AI cognition, such as a cognitive-amplification-versus-delegation framework with dependency and drift metrics (Di Santi, 2026), measure the sustainability of reliance rather than teachable skills. Field accounts of how skilled users work, the continuous push-back-and-validate "Cyborg" mode (Randazzo et al., 2025) and the skill-dependence of AI's value at the competence frontier (Dell'Acqua et al., 2023), describe the behaviour that CoRe-3 decomposes into assessable skills.
Table 1 makes the boundary explicit by mapping each nearest prior framework's constructs onto Framing, Judging, and Steering. The recurring pattern is that prior frameworks either (i) omit a construct, or (ii) fuse Framing and Steering into one "prompting/iteration" skill.
Table 1. Where prior frameworks place the three FJS skills (Framing, Judging, Steering).
| Prior framework | Framing (pre-generation) | Judging | Steering (post-generation) |
|---|---|---|---|
| 4D AI Fluency (Dakan & Feller, 2025) | Delegation + part of Description | Discernment | fused into Description |
| Metacognitive demands (Tankelevitch et al., 2024) | "prompting" (as a demand, not a skill) | "evaluating outputs" | "workflow iteration" |
| Prompt literacy / CLEAR (Lo, 2023) | fused into "prompting" | weakly present | fused into "iterative refinement" |
| AI literacy (Long & Magerko, 2020; UNESCO, 2024) | absent | diffuse "critical evaluation" | absent |
| Cyborg/Centaur modes (Randazzo et al., 2025) | "directed" mode (described, not assessed) | "push back / validate" | "continuous dialogue" |
No prior column cleanly separates the pre-generation and post-generation skills and treats all three as independently scored competencies. That conjunction is the contribution.
Validated instruments and evaluative judgement. Psychometric GenAI-competence scales such as GenAIComp (Lee et al., 2025) and tests such as GLAT (Jin et al., 2024) establish that GenAI competence is measurable, but their factor structures are literacy-oriented and isolate no Framing, Judging, or Steering construct; the work closest to ours pairs AI-collaboration literacy with metacognition (Sidra & Mason, 2025) yet posits correlated factors rather than demonstrating dissociation. Because rubric-based LLM grading can agree highly with humans yet diverge on subjective criteria (Yavuz et al., 2025), our multitrait-multimethod design across three grader backends (Section 8) treats grader-method variance as a measured term. Our Judging skill operationalizes the evaluative judgement argued to be the core human capability for the AI era (Bearman et al., 2024; Walton et al., 2025): critical evaluation is the highest-load activity in AI-assisted writing (Yao & Fan, 2025) and users default to uncritical acceptance without intervention (Wingerter et al., 2025), which is why we treat it as one of three separable skills rather than one overarching disposition. Among named frameworks, the eight-dimension AI Quotient (Ganuthula & Balaraman, 2025) leaves prompt-engineering fused, whereas CoRe-3 splits it into pre-generation Framing and post-generation Steering; assessment-mode partitions of coursework (Elshall & Badir, 2025) are orthogonal and complementary.
Problem formulation as the AI-era skill. As models absorb execution, a prominent strand argues the durable human skill shifts to problem formulation (Acar, 2023), precisely our Framing construct; classroom work assesses it through prompt problems (Denny et al., 2024), question formulation (Kim et al., 2025), and problem decomposition (Srinath et al., 2025), and the older problem-finding literature established it as separable from problem solving (Runco & Chand, 1995). We build on this strand by placing Framing in a measured loop with Judging and Steering.
One-line novelty. CoRe-3 is, to our knowledge, the first theoretically-grounded decomposition of productive generative-AI use into three independently-assessable competencies that separates pre-generation Framing from post-generation Steering, with feasibility evidence that the three skills dissociate. The contribution is the separation itself, which is both theoretically motivated (monitor-control plus an upstream task definition) and empirically consequential (the skills can be measured apart).
The framework is instantiated in CoReasoningLab, a runnable open-source web platform that maps the abstract skills onto a concrete learner experience. It is a Node/Express application with role-based access (student, instructor, administrator), a challenge database, practice and assessment modes, multiple-choice and open-ended response formats, and a five-language content library (English, Hebrew, German, Spanish, French). Its full source, the web application, the database schema, the content library, and the scoring engine of 16 prompts (Section 7.1), is released, alongside a pedagogical-foundations document; the Additional file 1 walks through the running system. All challenges evaluated here are English-language (Section 9.2), and the quantitative results come from the scoring engine over controlled inputs, not production logs.
Because challenge generation, rubric generation, and scoring are themselves prompt-defined, the engine extends to a new subject, language, or grader backend by substitution rather than redesign, and the released artifact lets others add their own. The platform is therefore domain-general: not a computing-education tool but a generic instrument for any discipline in which a learner must specify an ill-defined task, judge a fallible solution, and steer it toward a better one. Its released content already spans 12 disciplines across STEM, the social sciences, the humanities, law, and professional fields (Additional file 1). An educator authors a challenge by naming a subject; the system generates the ill-defined problem, the three per-skill rubrics, and the seeded-flaw solution.
Authoring flow (instructor). An instructor defines a challenge by choosing a course and subject path; the system then generates the ill-defined problem, the three per-skill rubrics, the gold-standard framing, and the seeded-flaw solution that the learner will critique (Section 7.1). Challenges are organized into courses and can be assigned to cohorts.
Learner flow (student). A student enters a challenge run with two phases, walked through step by step in the Additional file 1. In Phase 1 (Framing) the student refines the raw ill-defined problem, by writing refinement sections (assumptions, constraints, clarifications, success metrics) or selecting them in multiple-choice mode, and receives rubric-driven Framing feedback and a grade. The system then produces a plausible but deliberately flawed solution. In Phase 2 the student repeatedly judges the current output (flagging its issues) and steers the AI (issuing correction commands), up to a configured maximum, and marks the task complete when satisfied. Framing, Judging, and Steering are scored separately, each with its own rubric-driven feedback, and surfaced in a per-challenge report and longitudinal analytics that track the three skills independently. This separation in the interface, distinct phases, feedback channels, and grade columns, is the framework's central claim made operational: a learner sees, and is scored on, three different things, not one undifferentiated "AI use." The remainder of this section describes the instrument that produces those scores.
To show that the three constructs are not only conceptually distinct but practically measurable, we describe a working instrument that scores each skill from a learner's transcript. The instrument is a pipeline of large-language-model prompts; we use it here as an existence proof that automated, rubric-driven scoring of Framing, Judging, and Steering is feasible, not as a validated assessment.
Challenge construction. Each challenge begins with a deliberately ill-defined problem generated to contain two or three unstated gaps, recorded internally but never shown. A per-challenge set of three rubrics, one each for Framing, Judging, and Steering, is generated for the subject area, each with three to five measurable criteria and explicit excellent and poor indicators. A gold-standard "best framing" is generated as an internal reference. The design instantiates an inverted cognitive apprenticeship: rather than observing an expert, the learner is given a fallible artifact to repair. This connects the instrument to the instructional literature on learning from errors and erroneous examples, in which studying and correcting flawed solutions improves error detection and conceptual understanding relative to studying only correct ones (Große & Renkl, 2007; Durkin & Rittle-Johnson, 2012); CoRe-3 generalizes that paradigm from static worked examples to an interactive, learner-driven repair loop over AI output.
The deliberately-imperfect output. After the learner frames the task, the model produces a plausible, professional-looking solution that is required to embed two to four non-trivial issues, wrong-but-reasonable assumptions, missing edge cases, or subtle logical errors, each recorded internally with a severity label and none flagged to the learner. Across steering cycles, updates address the learner's commands but may introduce new minor issues, so that difficulty adapts to the quality of steering rather than collapsing to a perfect answer.
Scoring. Each skill is scored in two stages. A skill-specific evaluator assesses the learner's response against the (internal) rubric and produces per-criterion ratings on a three-point scale; a generic grading stage then aggregates those ratings into a final grade, weighting critical criteria more heavily rather than averaging. Crucially, the three evaluators differ in what they compare against: Framing is evaluated against the gold framing and the rubric; Judging is evaluated against the seeded ground-truth issues, yielding a recall/precision signal (issues correctly identified, missed, and falsely flagged); and Steering is evaluated against the trajectory of the output across cycles, rewarding corrections that demonstrably move the solution toward correctness. This is why the skills are measured apart: each evaluator interrogates a different referent.
The instrument used here is the scoring engine of the CoReasoningLab platform, a library of 16 prompts spanning challenge construction, AI generation, and evaluation (traced in the Supplementary Material). It carries the deployed application's evaluation logic verbatim, the same rubrics, criteria, and system prompts; the research harness (simulated-learner generation, the crossed factorial, and the analysis) only orchestrates that fixed logic over controlled inputs, so the measurements are reproducible and characterize the instrument itself. Because the grader is a language model, the results below characterize the instrument's internal behavior (whether it separates controlled competence levels and dissociates the skills); agreement with human experts is the separate validity question the prepared study in Section 9.3 addresses.
We exercise the instrument over controlled inputs to test three feasibility claims: that it discriminates competence, that the three skills dissociate (Proposition P3), and that the grader is self-consistent enough to report. The "learners" are simulated personas of controlled per-skill competence, generated by one model (gpt-4o-mini) and graded by a different model (gpt-4o), so that no model grades its own output. These claims concern the instrument; the agreement study with human expert graders is prepared and is the next stage (Section 9.3).
Design. We use a crossed factorial: each of the three skills is independently set to a strong or weak competence level, giving $2^3 = 8$ profiles, crossed with ten challenges across ten distinct subjects (spanning STEM, the social sciences, and the humanities), for 80 simulated learners. Framing and Steering responses are generated by the competence-conditioned learner model; Judging is operationalized by a competence-conditioned selection over the challenge's ground-truth seeded issues (a strong judge flags all real issues and no false ones; a weak judge flags few and adds false ones), which are themselves machine-generated and not yet human-verified. Because the manipulation is per skill, the design separates whether each grade tracks its own skill's competence (discrimination) from whether it is insensitive to the others' (dissociation).
Discrimination. Grades move monotonically with competence: the all-weak profile averages C on every skill, the all-strong profile averages between B and A, and each skill's grade rises when that skill is set to strong. The judging signal is mechanistically transparent: a strong judge flags all of the seeded issues with no false alarms and is graded A; a weak judge flags none and raises false issues and is graded C.
Dissociation (the central result). Table 2 reports, for each graded skill, the change in its mean grade (on a 3-point scale, A=3..C=1) when each skill in turn is moved from weak to strong. The result that carries the claim is the two blind-graded skills, Framing and Steering, whose free-text responses the grader scores without knowing the intended competence: each shows a clear positive own-effect (+0.62 and +0.43) with near-zero cross-effects, so a simulated learner's two free-text grades move independently. Judging's own-effect (+2.00) is large but fixed by construction: its competence is operationalized by a controlled selection over the challenge's seeded issues, and those seeded issues are themselves machine-generated and not yet human-verified (Section 9.2). We therefore read Judging's clean diagonal as a controlled check that the grader correctly rewards recall and precision, not as independent evidence that the skills separate. The off-diagonal (cross-skill) effects average +0.01 across the matrix, so each grade responds to its own skill and is essentially flat in the others (Figure 3).
Table 2. Effect on each skill's grade of manipulating each skill's competence (grade Δ, strong − weak; N=80).
| grade of ↓ \ manipulated → | Framing | Judging | Steering |
|---|---|---|---|
| Framing | +0.62 | −0.02 | −0.07 |
| Judging | +0.00 | +2.00 | +0.00 |
| Steering | −0.12 | +0.27 | +0.43 |
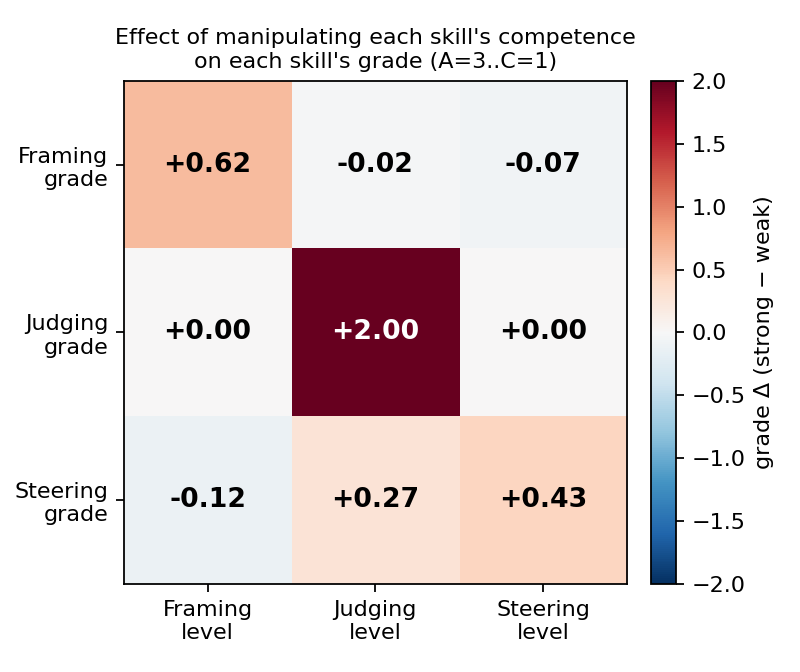
Figure 3. Effect of manipulating each skill's competence (columns) on each skill's grade (rows). Each cell is the grade change (strong minus weak) on the 3-point scale (A=3, B=2, C=1); warmer cells are larger positive effects. The diagonal (own-skill effect) dominates; off-diagonal (cross-skill) effects are near zero.
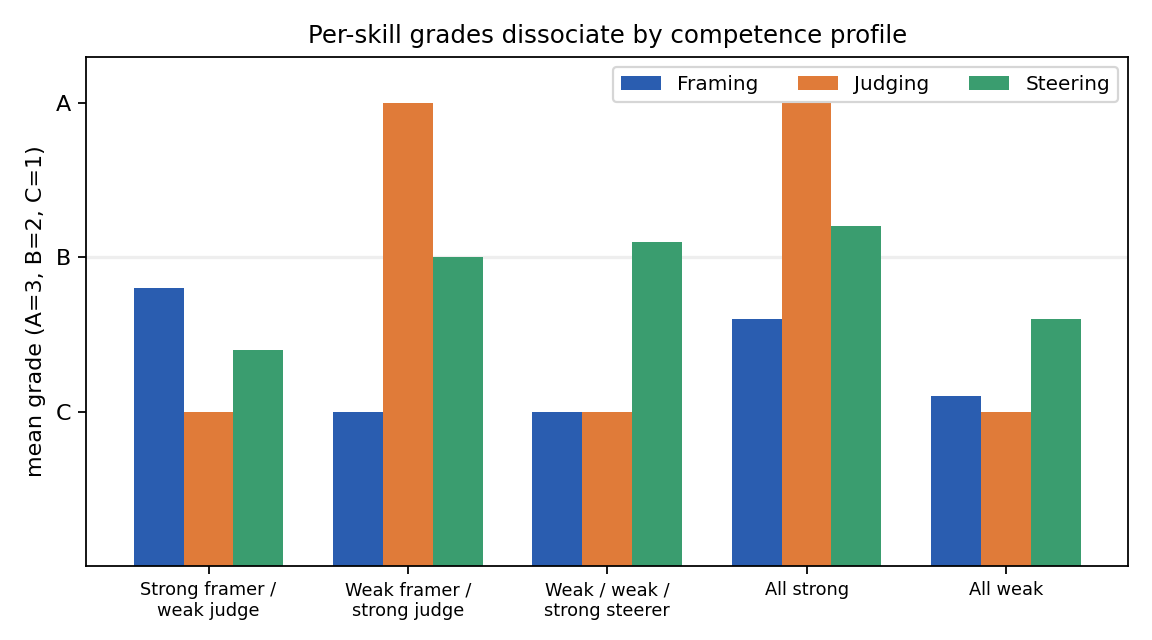
Figure 4. Mean per-skill grade for five competence profiles. Judging reaches A only when judging is strong, regardless of framing or steering; each skill responds to its own competence.
The diagonal (own-skill) effects are statistically reliable: bootstrap 95% confidence intervals (2,000 resamples) exclude zero for Framing (+0.62, CI [+0.46, +0.77]) and Steering (+0.43, CI [+0.20, +0.65]); Judging is deterministic by construction (+2.00). The same separation appears in the inter-skill grade correlations across the 80 learners: Framing-Judging $\rho = -0.03$ ($p = 0.82$) and Framing-Steering $\rho = -0.12$ ($p = 0.29$) are both non-significant, while Judging-Steering $\rho = +0.25$ ($p = 0.02$) is positive and significant. The Framing-Judging pair is the decisive demonstration: these two skills are scored by entirely separate mechanisms (free-text framing evaluation versus issue-selection judging) yet their grades are uncorrelated, which a single general-ability account cannot produce. The Judging-Steering correlation behaves exactly as Proposition P2 predicts, the expected ceiling relation in which judging gates steering, and so is consistent with, rather than evidence against, separability. With only three indicators a formal factor model is under-identified, so we rest the separability evidence on the manipulation-based effect matrix and the inter-skill correlations rather than on a confirmatory dimensionality test.
Convergent and discriminant validity (a multitrait-multimethod view). The result so far is a discriminant-validity finding: three traits separate. Construct validity also requires the convergent property, that the same skill measured by different methods agrees, and that the instrument reports correlation when the underlying competence really is shared (Campbell & Fiske, 1959). Two analyses supply it. First, we treat the three grader backends (gpt-4o, gpt-4o-mini, and the independent-vendor llama-3.3-70b) as independent methods. For the two skills with the widest grade range, the same skill agrees across graders while different skills stay near zero (Table 3, Panel A), the convergent-high / discriminant-low pattern a valid measure should show. Steering's narrower range under the P2 ceiling gives a lower cross-method correlation, a restriction of variance rather than a separate construct. Across the full matrix the convergent correlations exceed both heterotrait terms and no grader shows halo, so all three Campbell-Fiske criteria hold. Second, the instrument is faithful to the population's dependence structure (Table 3, Panel B): on learners whose competences are set independently the inter-skill grade correlations are near zero, whereas on the 20 learners whose competences are all strong or all weak the same instrument returns positive correlations. It therefore does not manufacture dissociation, recovering independence when the competences are independent and correlation when they are shared, which licenses reading the crossed-design separation as a property of the skills rather than of the scoring.
Table 3. Multitrait-multimethod validity. Panel A: convergent agreement of the same skill across the three grader backends (mean pairwise per-learner rank correlation on the 40 shared transcripts). Panel B: inter-skill grade correlation by population, showing the instrument recovers the population's dependence structure (discriminant on the full crossed design, convergent on the n=20 all-strong and all-weak learners whose three competences share one level).
| Panel A: cross-grader convergent ($\rho$, 3 backends) | Framing | Judging | Steering |
|---|---|---|---|
| same skill across gpt-4o, gpt-4o-mini, llama-3.3-70b | +0.57 | +0.67 | +0.21 |
| Panel B: inter-skill $\rho$ by population | F-J | F-S | J-S | summary |
|---|---|---|---|---|
| independent (crossed) competences | −0.03 | −0.12 | +0.25 | mean $\lvert\rho\rvert$ = 0.13 |
| shared single-ability level | +0.52 | +0.14 | +0.56 | mean $\rho$ = +0.41 |
The own-skill effects are directionally consistent across subjects: Framing and Steering each show a positive own-competence effect in nine of the 10 subject areas, the two exceptions reflecting the small per-subject sample rather than a sign reversal (Judging is fixed by construction throughout). The designed-contrast personas make the separation concrete (Figure 4): a weak-framer / strong-judge learner scores Framing C but Judging A; a strong-framer / weak-judge learner inverts this; and a weak / weak / strong-steerer elevates only Steering. A single underlying "AI-use ability" cannot produce these crossed profiles. Converging evidence comes from outside our synthetic setting: in an intervention study, students' behavioral regulation of LLM use predicts effective use whereas self-rated AI expertise does not (Clerc et al., 2026), so the skill of working with AI is distinct from a general, self-assessed competence.
Robustness and ablations. Three checks, reported in full in the Additional file 1, support the result. First, the grader is 92% self-consistent on repeat, a precision check, not accuracy against humans. Second, the dissociation replicates across three grader backends spanning two providers (gpt-4o, gpt-4o-mini, and Meta's llama-3.3-70b; diagonal-to-off-diagonal ratio 39), so it does not hinge on one model snapshot. Third, a ground-truth ablation shows Framing and Steering are scored by rubric-guided model judgment while Judging, as instrumented, tracks the seeded answer key, which locates the Judging score to settings with known ground truth (Section 9.3 specifies the open-ended variant).
Scope. These results establish feasibility, with four qualifications. Judging's clean diagonal (+2.00, zero cross-effects) is a controlled check by design, so the independent separation evidence is carried by the free-text, blind-graded Framing and Steering (own-effects +0.62 and +0.43 with near-zero cross-effects). The dissociation replicates across grader backends from two providers (Supplementary Material), while agreement with human experts is the validity step the prepared study of Section 9.3 supplies. With three constructs the evidence rests on the manipulation-based effect matrix and the inter-skill correlations, the appropriate tests for this design. Finally, Steering's own-effect is governed by the P2 ceiling by design (its quality is bounded by the judging that precedes it); this is a property of the construct, not the grader, since under a deliberately strict steering rubric the effect is unchanged (+0.40 versus +0.50) and the dissociation persists. Human steering data will trace this ceiling directly.
The feasibility demonstration establishes that the three skills are separable and automatically scoreable; this section reconciles the tensions the framework raises, bounds the present evidence, and specifies the validation program it invites.
Four tensions bear on the framework, each with a resolution within it.
Offloading versus productive struggle. Evidence that AI use can depress critical thinking through cognitive offloading (Gerlich, 2025; Kosmyna et al., 2025) appears to threaten any framework that puts learners in close partnership with AI. The resolution is in the zone-of-proximal-development stance: CoRe-3 treats the AI as a mediating tool whose purpose is the learner's eventual independence, and it offloads execution while deliberately retaining the cognitive work of specifying, evaluating, and correcting. The framework is, in this sense, the designed inverse of metacognitive laziness (Proposition P5). Whether exercising the loop actually reduces the offloading signatures is an empirical question this paper does not test; it is reserved for the efficacy study of Section 9.3.
The calibration trap. Judging is metacognitive monitoring, and monitoring is only useful when calibrated. A learner who lacks the domain knowledge to recognize an error cannot detect that error in AI output, however vigilant. Judging is therefore bounded by domain competence, and the framework should be read as describing a skill that develops with domain knowledge, not as a substitute for it (Proposition P4).
Interactive is not automatically productive. ICAP predicts that interactive engagement yields the most learning, but rapid AI dialogue can be voluminous and shallow, a sequence of re-rolls rather than reasoning. Steering counts as genuine metacognitive control only when corrections are knowledge-generating, which is why the instrument rewards targeted, convergent corrections rather than mere repetition.
Standards can regress. Judging and Steering presuppose that the learner holds standards adequate to evaluate the output. When the AI is more competent in the domain than the learner, the standards the learner applies may be inferior to the artifact under review, a reversal that classical formative-assessment theory does not anticipate and that bounds the framework's applicability at the expert frontier.
This is a conceptual contribution with a working instrument, and three boundary conditions define where the present evidence applies. The feasibility demonstration uses simulated learners of controlled competence: they establish that the grader carries signal and that the skills separate, and they set up the human-learner studies of Section 9.3. To keep generation and grading independent, learners are generated by one model (gpt-4o-mini) and graded by another (gpt-4o), and the dissociation replicates across grader backends spanning two providers (Section 8); broadening the grader pool further is part of the validation program. The challenges are English-language, and agreement with human experts is the defined next step (Section 9.3). Two construct-specific boundaries are worth stating. First, Judging as instrumented here is scored against a seeded answer key, so the Judging score applies to settings with known ground truth; open-ended scoring without a key is a distinct instrumentation that Section 9.3 specifies. Second, Steering's signal is governed by the P2 ceiling by design (its quality is capped by the judging it follows), a relation that human steering data will trace directly. What the paper establishes is a theoretically-grounded decomposition with stated propositions, a precise novelty boundary, and evidence that the three constructs are separable and automatically scoreable; the efficacy study of learning outcomes is the next stage of the program.
The feasibility demonstration shows that the constructs are separable and measurable; it does not establish that the automated grades match expert human judgment, nor that exercising the skills improves learning. We therefore specify the validation program the framework invites, organized as an argument-based validity case in the sense of Messick (1995) and Kane (2013): the present evidence supports the scoring and generalization inferences (the instrument scores consistently and the three constructs separate), while the extrapolation inference (that the scores reflect a human competency that transfers) and the implication inference (that the scores support instructional decisions) remain to be established by the studies below.
First, an instrument-validity study, built and ready to run. Three blind expert raters re-grade a stratified sample of 40 transcripts (covering all eight competence profiles) on the three skills using the per-skill rubrics; inter-rater reliability is reported as ordinal Krippendorff's $\alpha$ (primary, since the grades are ordinal), Fleiss' $\kappa$, and pairwise Cohen's $\kappa$, and agreement of the human majority with the automated grade as Cohen's $\kappa$ and ordinal $\alpha$ per skill, against the field-typical bar of $0.6$ to $0.8$. With all three raters scoring the same 40 items the agreement estimate has a bootstrap half-width on the order of $\pm 0.1$, enough to place each skill inside or outside that band. This step is indispensable rather than a formality: recent work shows that LLM-as-judge agreement with human experts is moderate and task-dependent, sometimes falling to Fleiss' $\kappa$ near $0.1$ to $0.3$ on hard rubric judgments (Feng et al., 2025), so automated grades are validated against humans rather than assumed reliable. The package confronts the recursive calibration threat (who grades the grader) on a second level: because the Judging construct rests on machine-seeded ground-truth issues, a parallel task has the same three raters verify a balanced set of 40 seeded issues (20 real and 20 distractor controls) as genuine flaws, yielding a confirmation rate for the Judging ground truth before its recall/precision signal is trusted. The full package, codebook, per-rater shuffled task files with hidden ground truth, and seed-fixed agreement-scoring scripts, is released and reproducible, so the study runs directly once raters are recruited. Second, a construct-validity study at scale (target of at least 200 real learners) to test Propositions P1 through P4, examining whether Framing, Judging, and Steering dissociate across a learner population and whether the proposed gating relations hold. Third, a grader-robustness study across multiple model backends to separate the framework's signal from any single model's idiosyncrasies. Only an efficacy study with real learners can test Proposition P5 and any learning claim; that is explicitly outside the present scope.
Beyond validity, the framework opens a research program, and one strand can begin before the human studies: external validity can be probed by scoring a released corpus of real student-LLM dialogue, the StudyChat dataset of 16,851 student-ChatGPT interactions from a university course (McNichols et al., 2025), with the per-skill instrument, testing whether Framing, Judging, and Steering are detectable and separable outside the controlled challenge format; StudyChat's own dialogue-act labels (questioning, verification, and editing) align with the three skills and supply an external anchor. Four further directions follow from the propositions: a longitudinal study of whether the three skills develop and persist with practice; an instructional-intervention study testing whether targeted teaching of each skill improves it, building on evidence that students' behavioral regulation of LLM use is trainable (Clerc et al., 2026); a transfer study testing P4's prediction that Framing, the more structural skill, transfers across domains more readily than the domain-bound Judging, a question made tractable by evidence that metacognitive regulation can show far transfer (Wirth et al., 2025); and a mediation study testing whether metacognitive monitoring accuracy predicts Judging, extending findings that calibration predicts subsequent strategy use in computer-based learning (Lee & Bosch, 2025) and tying the construct to its monitor-control grounding.
The decomposition is immediately actionable for higher education. An instructor can diagnose which cognitive operation a student's AI use failed at and give per-skill formative feedback, rather than a single "prompting" grade; a programme can define reasoning with generative AI as an assessable learning outcome and track it across a curriculum; and academic-integrity policy can shift from prohibiting AI use toward assessing the framing, judging, and steering that competent use requires. The released, discipline-general platform lets any department instantiate this without building an instrument.
The task of education in the age of generative AI is not to produce faster answer-getters but to cultivate critical collaborators: learners who can specify a problem worth solving, judge what a machine returns, and steer it toward something better. That capability is teachable only if it can be named and assessed. CoRe-3 offers a decomposition of it into three theoretically-grounded, independently-assessable skills, Framing, Judging, and Steering, separates the pre-generation skill from the post-generation one in a way prior frameworks do not, and shows that the three can be measured apart. Because the decomposition tracks what a person must contribute rather than what today's models cannot yet do, it does not lapse as the models improve: the more capable the system, the more the assessable skill is the framing, judging, and steering of it. We release the model, the instrument, and the validation protocol as a foundation to build on: an open, domain-general platform with which a university educator in any discipline, from algorithms to applied ethics, can assess and train this skill, for the assessment and instruction the moment demands.
Availability of data and materials. The assessment instrument (the 16-prompt scoring engine), the experiment data, and the prepared human-rater validation protocol are released in a public repository (URL withheld to preserve anonymous review; available to the editors on request).
Competing interests. The authors declare that they have no competing interests.
Funding. The authors received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors for this research.
Authors' contributions. AA and YA jointly conceived the competency model, designed and implemented the instrument and experiments, analysed and interpreted the results, and drafted and critically revised the manuscript. Both authors read and approved the final manuscript.
Ethics approval and consent to participate. Not applicable. The study reports a feasibility demonstration over model-generated simulated learners and involves no human participants.
Consent for publication. Not applicable.
Use of generative AI. Generative AI is the assessment instrument evaluated in this paper (Section 7.1); no generative-AI tool was used to author the scholarly content of the manuscript.
Acknowledgements. Not applicable.
Additional file 1 — File format: DOCX (.docx). Title: Additional file 1, supplementary material. Description: a system walkthrough (screenshots of the running platform and the auto-generation-and-assessment pipeline), robustness and ablations (grader reliability, cross-vendor replication, and the ground-truth ablation), and a cross-disciplinary challenge showcase across twelve disciplines.
Acar, O. A. (2023, June 6). AI prompt engineering isn't the future. Harvard Business Review.
Anderson, L. W., & Krathwohl, D. R. (2001). A taxonomy for learning, teaching, and assessing: A revision of Bloom's taxonomy of educational objectives. Longman.
Annapureddy, R., Fornaroli, A., & Gatica-Perez, D. (2024). Generative AI literacy: Twelve defining competencies. Digital Government: Research and Practice.
Bansal, G., Wu, T., Zhou, J., Fok, R., Nushi, B., Kamar, E., Ribeiro, M. T., & Weld, D. S. (2021). Does the whole exceed its parts? The effect of AI explanations on complementary team performance. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems.
Barzilai, S., & Chinn, C. A. (2018). On the goals of epistemic education: Promoting apt epistemic performance. Journal of the Learning Sciences, 27(3), 353–389.
Bearman, M., Tai, J., Dawson, P., Boud, D., & Ajjawi, R. (2024). Developing evaluative judgement for a time of generative artificial intelligence. Assessment & Evaluation in Higher Education, 49(6), 893–905. https://doi.org/10.1080/02602938.2024.2335321
Bjork, E. L., & Bjork, R. A. (2011). Making things hard on yourself, but in a good way: Creating desirable difficulties to enhance learning. Psychology and the Real World, 56–64.
Buçinca, Z., Malaya, M. B., & Gajos, K. Z. (2021). To trust or to think: Cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW1), 1–21.
Campbell, D. T., & Fiske, D. W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56(2), 81–105.
Chi, M. T. H., & Wylie, R. (2014). The ICAP framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist, 49(4), 219–243.
Clerc, O., Abdelghani, R., Desvaux, C., Poisson, E., Oudeyer, P., & Sauzéon, H. (2026). Teaching students to question the machine: An AI literacy intervention improves students' regulation of LLM use in a science task. arXiv preprint arXiv:2604.01955.
Collins, A., Brown, J. S., & Newman, S. E. (1989). Cognitive apprenticeship: Teaching the crafts of reading, writing, and mathematics. Knowing, Learning, and Instruction: Essays in Honor of Robert Glaser, 453–494.
Dakan, R., & Feller, J. (2025). Framework for AI fluency. Anthropic.
Dell'Acqua, F., McFowland III, E., Mollick, E., Lifshitz-Assaf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F., & Lakhani, K. R. (2023). Navigating the jagged technological frontier. Harvard Business School Working Paper 24-013.
Denny, P., Leinonen, J., Prather, J., Luxton-Reilly, A., Amarouche, T., Becker, B. A., & Reeves, B. N. (2024). Prompt problems: A new programming exercise for the generative AI era. Proceedings of the 55th ACM Technical Symposium on Computer Science Education (SIGCSE).
Di Santi, E. (2026). Cognitive amplification vs cognitive delegation in human-AI systems: A metric framework. arXiv preprint arXiv:2603.18677.
Durkin, K., & Rittle-Johnson, B. (2012). The effectiveness of using incorrect examples to support learning about decimal magnitude. Learning and Instruction, 22(3), 206–214. https://doi.org/10.1016/j.learninstruc.2011.11.001
Elshall, A. S., & Badir, A. (2025). Balancing AI-assisted learning and traditional assessment: The FACT assessment in environmental data science education. Frontiers in Education, 10, 1596462. https://doi.org/10.3389/feduc.2025.1596462
Facione, P. A. (1990). Critical thinking: A statement of expert consensus for purposes of educational assessment and instruction (the Delphi report). American Philosophical Association.
Fan, Y., Tang, L., Le, H., Shen, K., Tan, S., Zhao, Y., Shen, Y., Li, X., & Gašević, D. (2025). Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance. British Journal of Educational Technology, 56(2), 489–530. https://doi.org/10.1111/bjet.13544
Feng, Y., Wang, S., Cheng, Z., Wan, Y., & Chen, D. (2025). Are we on the right way to assessing LLM-as-a-judge? arXiv preprint arXiv:2512.16041.
Fernandes, D., Villa, S., Nicholls, S., Haavisto, O., Buschek, D., Schmidt, A., Kosch, T., Shen, C., & Welsch, R. (2024). Performance and metacognition disconnect when reasoning in human-AI interaction. arXiv preprint arXiv:2409.16708.
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry. American Psychologist, 34(10), 906–911.
Ganuthula, V. R. R., & Balaraman, K. K. (2025). Artificial intelligence quotient framework for measuring human collaboration with artificial intelligence. Discover Artificial Intelligence, 5, 268. https://doi.org/10.1007/s44163-025-00516-1
Gerlich, M. (2025). AI tools in society: Impacts on cognitive offloading and the future of critical thinking. Societies, 15(1), 6.
Gilson, L. L., & Goldberg, C. B. (2015). Editors' comment: So, what is a conceptual paper? Group & Organization Management, 40(2), 127–130. https://doi.org/10.1177/1059601115576425
Große, C. S., & Renkl, A. (2007). Finding and fixing errors in worked examples: Can this foster learning outcomes? Learning and Instruction, 17(6), 612–634. https://doi.org/10.1016/j.learninstruc.2007.09.008
Gu, X., & Ericson, B. J. (2025). AI literacy in K-12 and higher education in the wake of generative AI: An integrative review. Proceedings of the 2025 ACM Conference on International Computing Education Research (ICER), 125–140. https://doi.org/10.1145/3702652.3744217
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research, 77(1), 81–112.
Jaakkola, E. (2020). Designing conceptual articles: Four approaches. AMS Review, 10, 18–26.
Jin, Y., Martinez-Maldonado, R., Gašević, D., & Yan, L. (2024). GLAT: The generative AI literacy assessment test. arXiv preprint arXiv:2411.00283.
Kane, M. T. (2013). Validating the interpretations and uses of test scores. Journal of Educational Measurement, 50(1), 1–73. https://doi.org/10.1111/jedm.12000
Kapur, M. (2008). Productive failure. Cognition and Instruction, 26(3), 379–424.
Kim, P., Wang, W., & Bonk, C. J. (2025). Generative AI as a coach to help students enhance proficiency in question formulation. Journal of Educational Computing Research, 63(3), 565–586. https://doi.org/10.1177/07356331251314222
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X., Beresnitzky, A. V., Braunstein, I., & Maes, P. (2025). Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing task. arXiv preprint arXiv:2506.08872.
Lee, H., & Bosch, N. (2025). Calibration discrepancy predicts students' subsequent metacognitive strategy use in computer-based learning environments. International Journal of Artificial Intelligence in Education, 35(6), 3746–3779. https://doi.org/10.1007/s40593-025-00514-5
Lee, J. D., & See, K. A. (2004). Trust in automation: Designing for appropriate reliance. Human Factors, 46(1), 50–80.
Lee, S. C., Baby, T., Vongvit, R., Lee, J., Kim, Y., Min, C., & Yoon, S. H. (2025). Development and validation of a generative AI competence scale. Technology in Society. https://doi.org/10.1016/j.techsoc.2025.103059
Li, C., Cui, H., & Hagedorn, L. S. (2026). The cognitive impact of ChatGPT in higher education: A systematic review of critical and creative thinking outcomes. Computers and Education: Artificial Intelligence, 10, 100571. https://doi.org/10.1016/j.caeai.2026.100571
Lo, L. S. (2023). The CLEAR path: A framework for enhancing information literacy through prompt engineering. The Journal of Academic Librarianship, 49(4).
Long, D., & Magerko, B. (2020). What is AI literacy? Competencies and design considerations. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 1–16.
McNichols, H., Ikram, F., & Lan, A. (2025). The StudyChat dataset: Student dialogues with ChatGPT in an artificial intelligence course. arXiv preprint arXiv:2503.07928. https://doi.org/10.48550/arXiv.2503.07928
Messick, S. (1995). Validity of psychological assessment: Validation of inferences from persons' responses and performances as scientific inquiry into score meaning. American Psychologist, 50(9), 741–749. https://doi.org/10.1037/0003-066X.50.9.741
Nazaretsky, T., Gabbay, H., & Käser, T. (2025). Can students judge like experts? A large-scale study on AI and human personalized formative feedback. Computers and Education: Artificial Intelligence. https://doi.org/10.1016/j.caeai.2025.100533
Nelson, T. O., & Narens, L. (1990). Metamemory: A theoretical framework and new findings. The Psychology of Learning and Motivation, 26, 125–173.
Parasuraman, R., & Manzey, D. H. (2010). Complacency and bias in human use of automation: An attentional integration. Human Factors, 52(3), 381–410.
Paul, R., & Elder, L. (2006). The miniature guide to critical thinking: Concepts and tools. Foundation for Critical Thinking.
Randazzo, B., Lifshitz-Assaf, H., Kellogg, K., Dell'Acqua, F., Mollick, E., Candelon, F., & Lakhani, K. R. (2025). Cyborgs, Centaurs and Self-Automators: Modes of human-AI collaboration in knowledge work. Harvard Business School Working Paper 26-036.
Runco, M. A., & Chand, I. (1995). Cognition and creativity. Educational Psychology Review, 7(3), 243–267.
Sadler, D. R. (1989). Formative assessment and the design of instructional systems. Instructional Science, 18(2), 119–144.
Salomon, G., Perkins, D. N., & Globerson, T. (1991). Partners in cognition: Extending human intelligence with intelligent technologies. Educational Researcher, 20(3), 2–9.
Sidra, S., & Mason, C. (2025). Generative AI in human-AI collaboration: Validation of the collaborative AI literacy and collaborative AI metacognition scales. International Journal of Human-Computer Interaction. https://doi.org/10.1080/10447318.2025.2543997
Sperber, D., Clément, F., Heintz, C., Mascaro, O., Mercier, H., Origgi, G., & Wilson, D. (2010). Epistemic vigilance. Mind & Language, 25(4), 359–393.
Srinath, S., Vadaparty, A., Smith IV, D. H., Porter, L., & Zingaro, D. (2025). Assessing problem decomposition in CS1 for the GenAI era. arXiv preprint arXiv:2511.05764.
Tankelevitch, L., Kewenig, V., Simkute, A., Scott, A. E., Sarkar, A., Sellen, A., & Rintel, S. (2024). The metacognitive demands and opportunities of generative AI. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems.
Tour, E., & Zadorozhnyy, A. (2025). Conceptualizing and operationalizing prompt literacy for English language learners. Journal of Adolescent & Adult Literacy. https://doi.org/10.1002/jaal.70020
UNESCO (2024). AI competency framework for students. UNESCO.
Vaccaro, M., Almaatouq, A., & Malone, T. (2024). When combinations of humans and AI are useful: A systematic review and meta-analysis. Nature Human Behaviour, 8, 2293–2303.
Vygotsky, L. S. (1978). Mind in society: The development of higher psychological processes. Harvard University Press.
Walton, J., Bearman, M., Crawford, N., Tai, J., & Boud, D. (2025). How university students work on assessment tasks with generative artificial intelligence: Matters of judgement. Assessment & Evaluation in Higher Education (advance online publication). https://doi.org/10.1080/02602938.2025.2570328
Wingerter, T. L., Straub, T., & Schweitzer, S. (2025). Mitigating automation bias in generative AI through nudges: A cognitive reflection test study. Procedia Computer Science, 270, 2106–2114. https://doi.org/10.1016/j.procs.2025.09.331
Winne, P. H., & Hadwin, A. F. (1998). Studying as self-regulated learning. Metacognition in Educational Theory and Practice, 277–304.
Wirth, J., Weber-Reuter, X.-L., Schuster, C., Fleischer, J., Leutner, D., & Stebner, F. (2025). Far transfer of metacognitive regulation: From cognitive learning strategy use to mental effort regulation. Educational Psychology Review, 37(1), 7. https://doi.org/10.1007/s10648-024-09983-x
Yao, G., & Fan, L. (2025). Cognitive load scale for AI-assisted L2 writing: Scale development and validation. Frontiers in Psychology, 16, 1666974. https://doi.org/10.3389/fpsyg.2025.1666974
Yavuz, F., Çelik, Ö., & Yavaş Çelik, G. (2025). Utilizing large language models for EFL essay grading: An examination of reliability and validity in rubric-based assessments. British Journal of Educational Technology, 56(4), 1–17. https://doi.org/10.1111/bjet.13494
Zimmerman, B. J. (2000). Attaining self-regulation: A social cognitive perspective. Handbook of Self-Regulation, 13–39.