1. Introduction
Reminiscence, the act of recalling and sharing personal memories, plays a central role in human social life. In clinical settings, reminiscence therapy has been shown to reduce depression and improve well-being in older adults [6, 7], while in archival contexts, recorded reminiscences preserve cultural and historical knowledge that would otherwise be lost [8]. A defining characteristic of reminiscence narratives is that speakers assume shared context with their audience: they reference people, places, and events through contextual cues rather than explicit naming, trusting the listener to fill in the gaps. This implicit referencing is natural in conversation but creates a fundamental challenge for automated systems that seek to index, search, or analyze these narratives.
Consider the following passage from a Japanese American reminiscence:
Entity-Grounded Narrative (EGN)
"The attack on Pearl Harbor was the event that changed everything for Japanese Americans like me. After December 7, 1941, suspicion and hatred grew, and we were treated as enemy aliens despite being American citizens. It was because of Pearl Harbor that the government issued Executive Order 9066 and started the forced relocation."
Entity-Elided Narrative (EEN)
"The surprise attack on a naval base in Hawaii was the event that changed everything for Japanese Americans like me. After December 7, 1941, suspicion and hatred grew, and we were treated as enemy aliens despite being American citizens. It was because of that attack that the government issued an order and started the forced relocation."
Gold entity: Attack on Pearl Harbor (Q52418) | Type: Event | Cues: December 7, 1941; naval base in Hawaii; Executive Order 9066; forced relocation
A human reader readily identifies the Attack on Pearl Harbor from the constellation of cues: the date, the Hawaiian naval base, the executive order, the internment of Japanese Americans. No single phrase names the entity; instead, recognition depends on integrating cultural, temporal, and historical knowledge distributed across the entire passage. This pattern of implicit entity reference is pervasive in reminiscence narratives, where speakers routinely allude to well-known people, places, and events without naming them, relying on shared background knowledge with their listener.
This phenomenon falls between existing NLP tasks without being addressed by any of them. Named Entity Recognition (NER) identifies explicitly mentioned entity spans in text [1, 2]. Entity Linking (EL) resolves those spans to knowledge base entries [3, 4]. Coreference resolution connects multiple references to the same entity but requires at least one explicit mention as an antecedent [5]. In implicit entity references, the entity is never named anywhere in the text; there is no span to extract, no mention to link, no antecedent to resolve. The task can be viewed as a form of zero-mention coreference: resolving a reference to an entity that has no surface realization in the text, only a distributed constellation of contextual cues.
While implicit entity recognition was first explored in short social-media text [21, 22], we extend it to a fundamentally different setting: long-form reminiscence narratives where entity cues are non-local, distributed across multiple clauses. We release IRC-Bench (Implicit Reminiscence Context Benchmark), a large-scale evaluation resource constructed from real reminiscence transcripts. This task addresses practical needs across multiple domains. Archives of personal reminiscences, including oral history collections containing millions of hours of recorded testimony, remain largely inaccessible to structured search because the entities discussed are rarely stated by name [9]. In healthcare, reminiscence therapy is a widely used intervention for older adults with dementia and depression [6, 7, 10]; automated systems that support these therapeutic conversations must identify the people and events being discussed even when the speaker does not name them. Social robotics and conversational AI for elderly companionship similarly require understanding implicit references to engage meaningfully with users' personal histories [11, 12]. More broadly, information retrieval over personal narratives requires understanding not just what is said, but what is meant.
Our contributions are as follows:
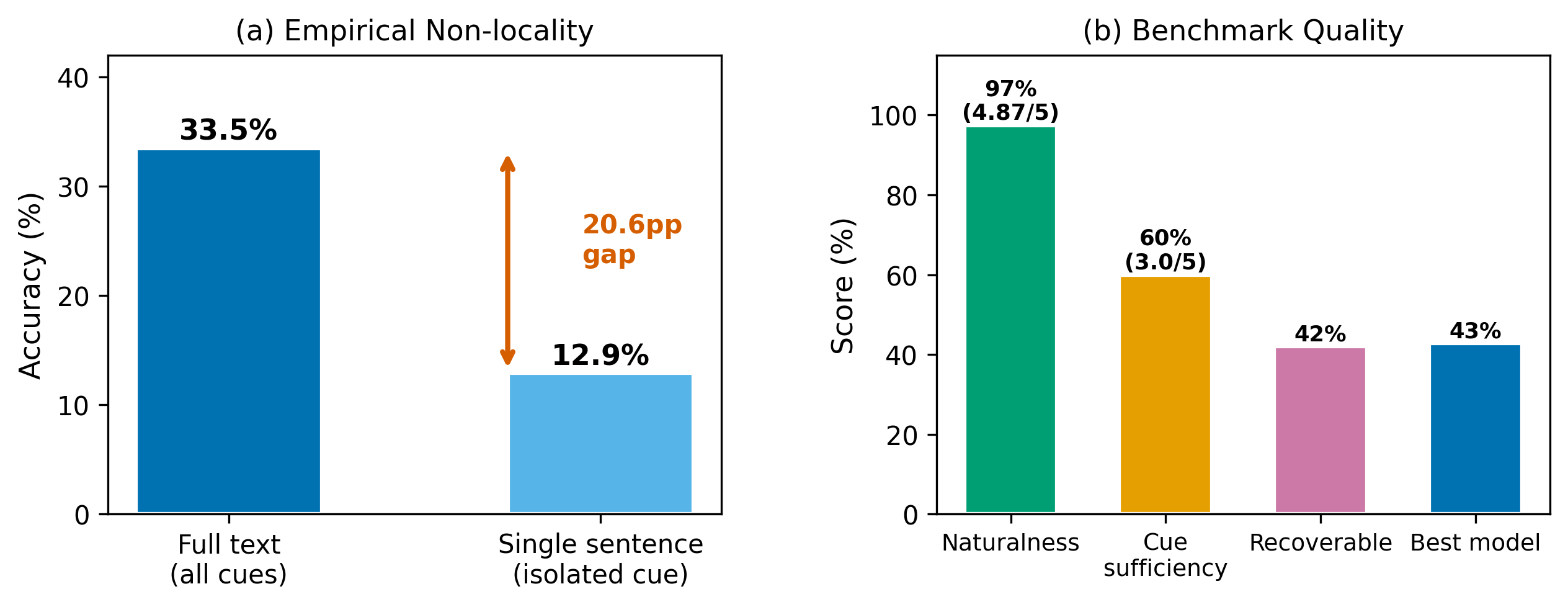
- Operationalizing non-locality at scale. Building on bridging-anaphora and zero-mention coreference literature [42, 43], we operationalize the non-locality property of implicit references: a formal definition (no contiguous span in the passage suffices to identify the entity, yet the union of non-contiguous cues does), a per-sample sentence-ablation diagnostic (full-text 33.5% vs. single-sentence 12.9% accuracy under GPT-4o zero-shot, n=200), and benchmark-scale evidence (25,136 samples) that this regime causes systematic failures in standard NER, EL, RAG, and CoT pipelines.
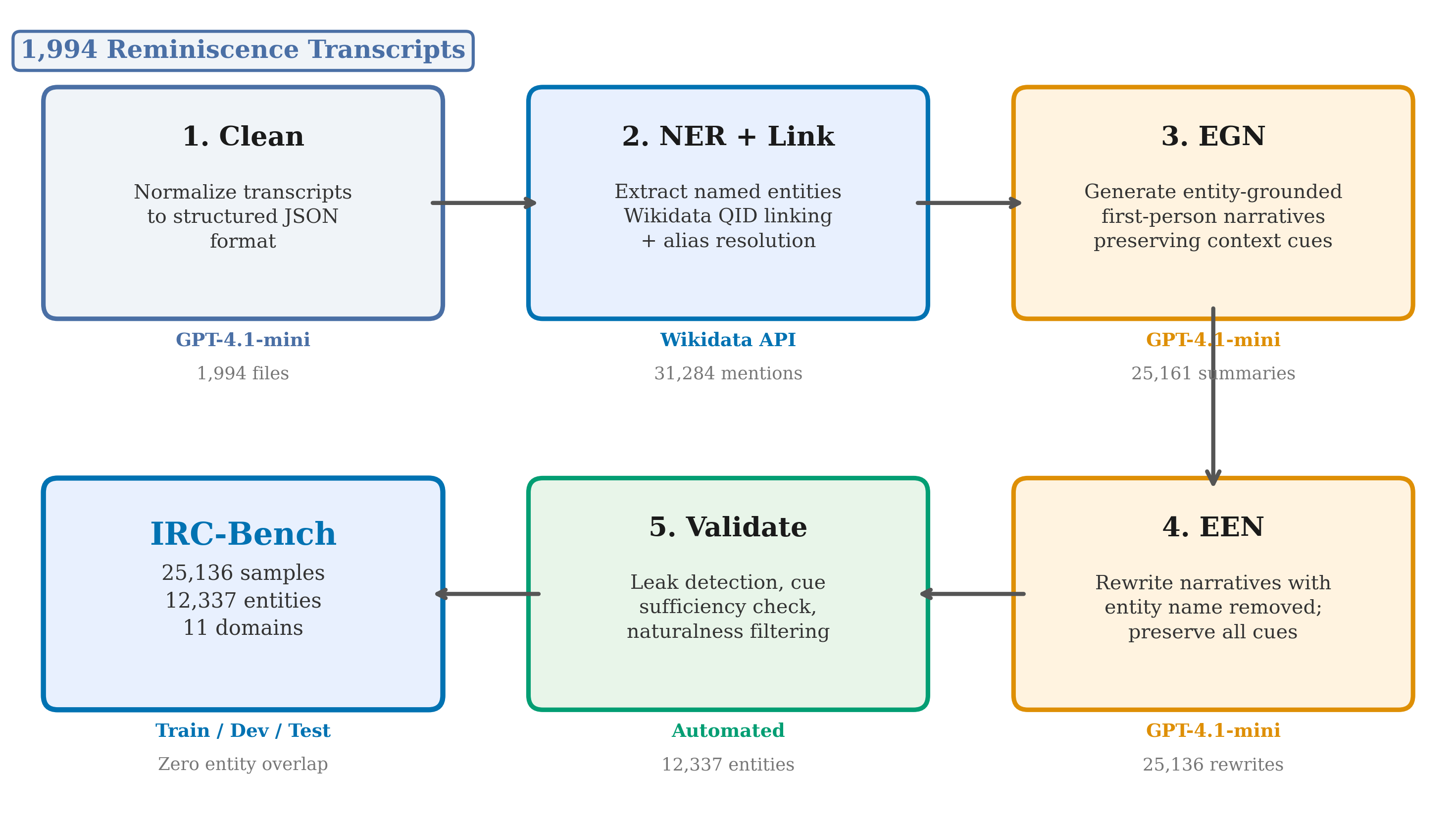
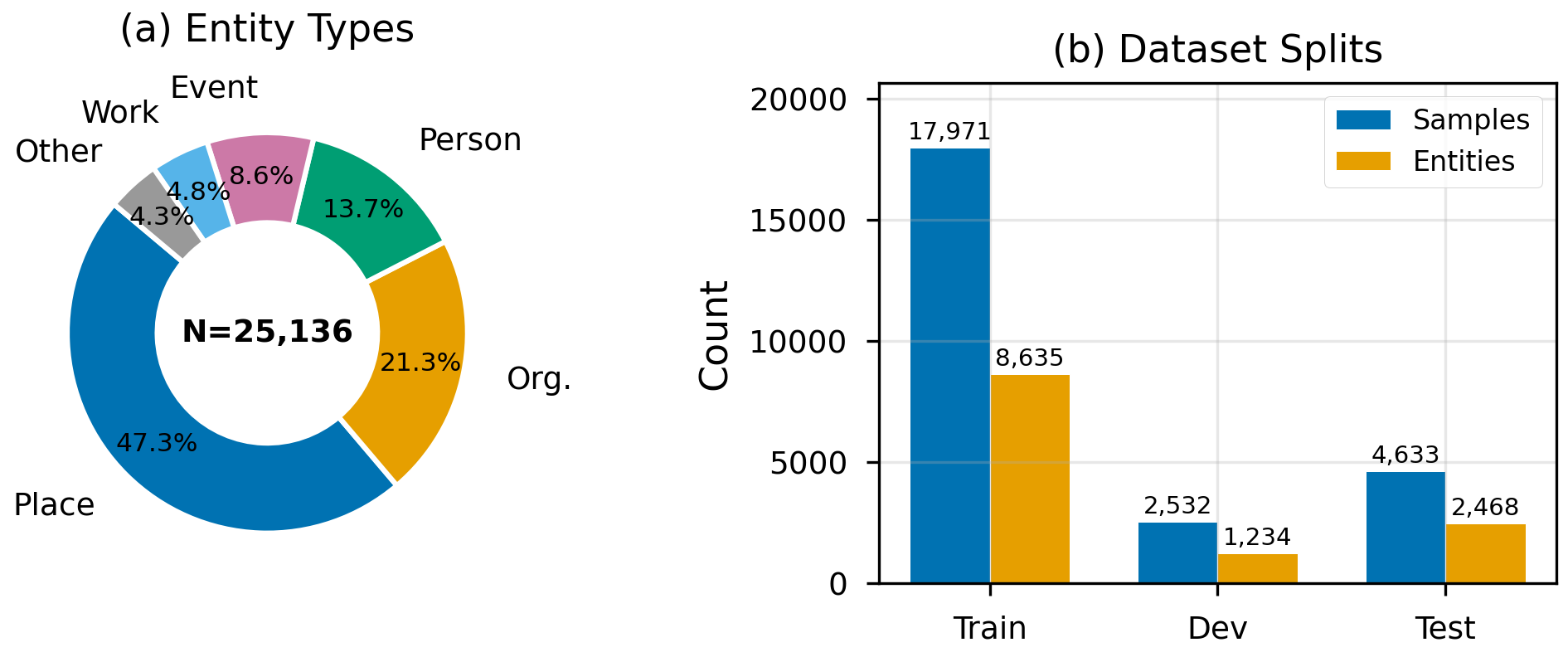
- IRC-Bench. We release IRC-Bench as a community evaluation resource: 25,136 implicit entity recognition samples derived from 12,337 unique Wikidata-linked entities sourced from 1,994 reminiscence transcripts across 11 thematic domains, with entity-level train/dev/test splits ensuring zero entity overlap between partitions. Each sample includes both an EGN and an EEN, along with entity metadata (QID, aliases, Wikipedia description). The release follows the NeurIPS Datasets and Benchmarks track convention; contributions (1) and (3) stand independently of the dataset release.
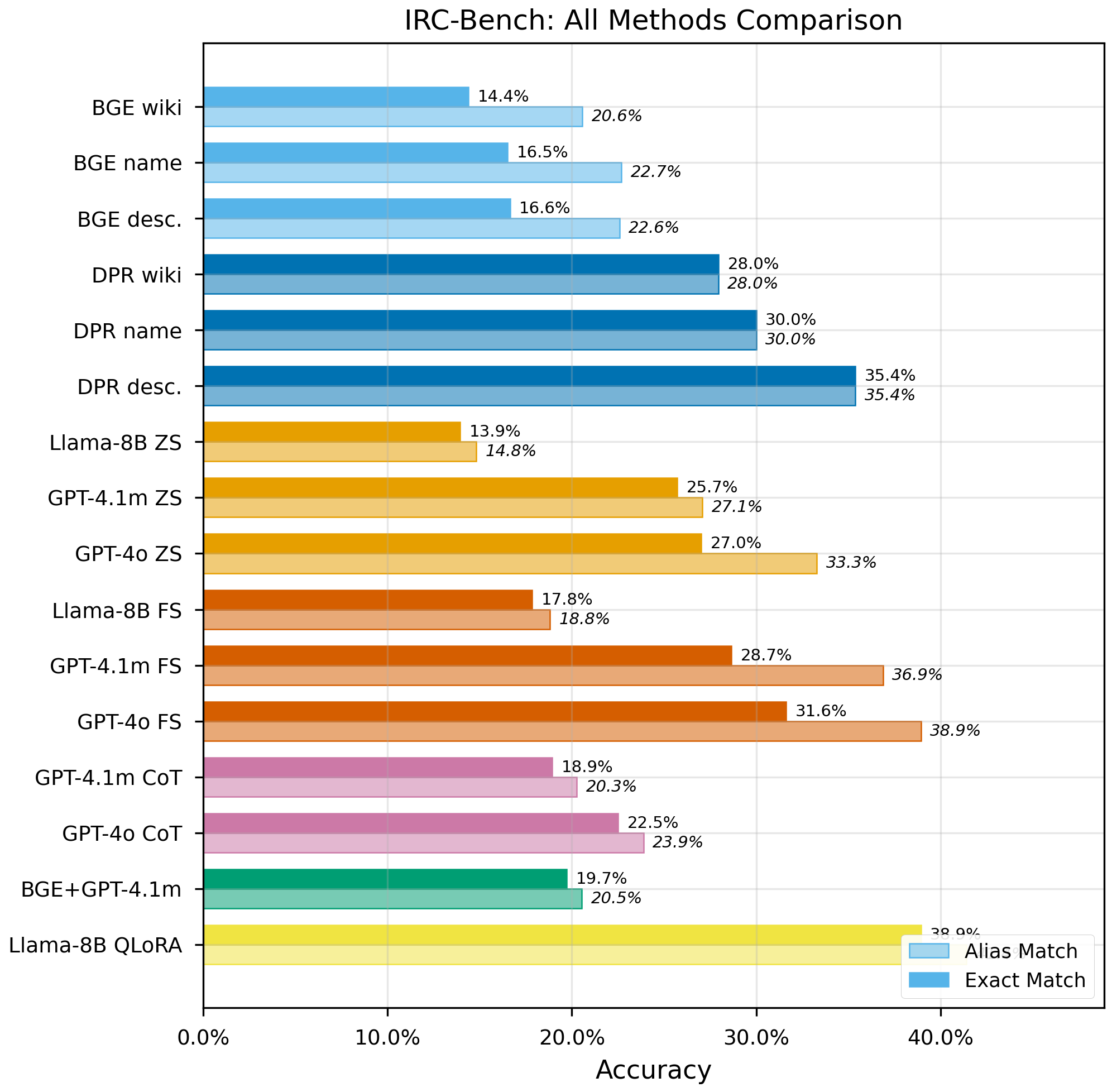
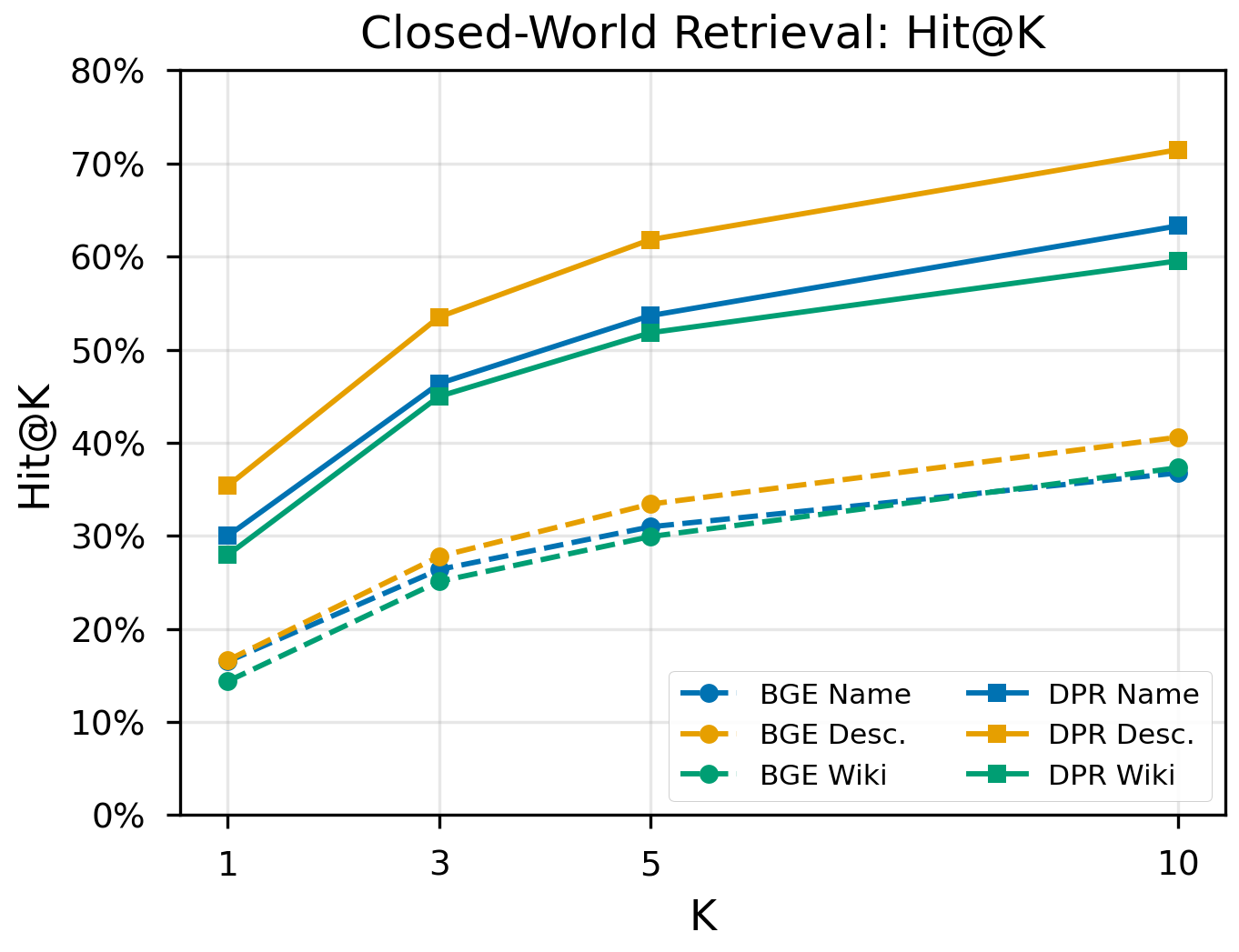
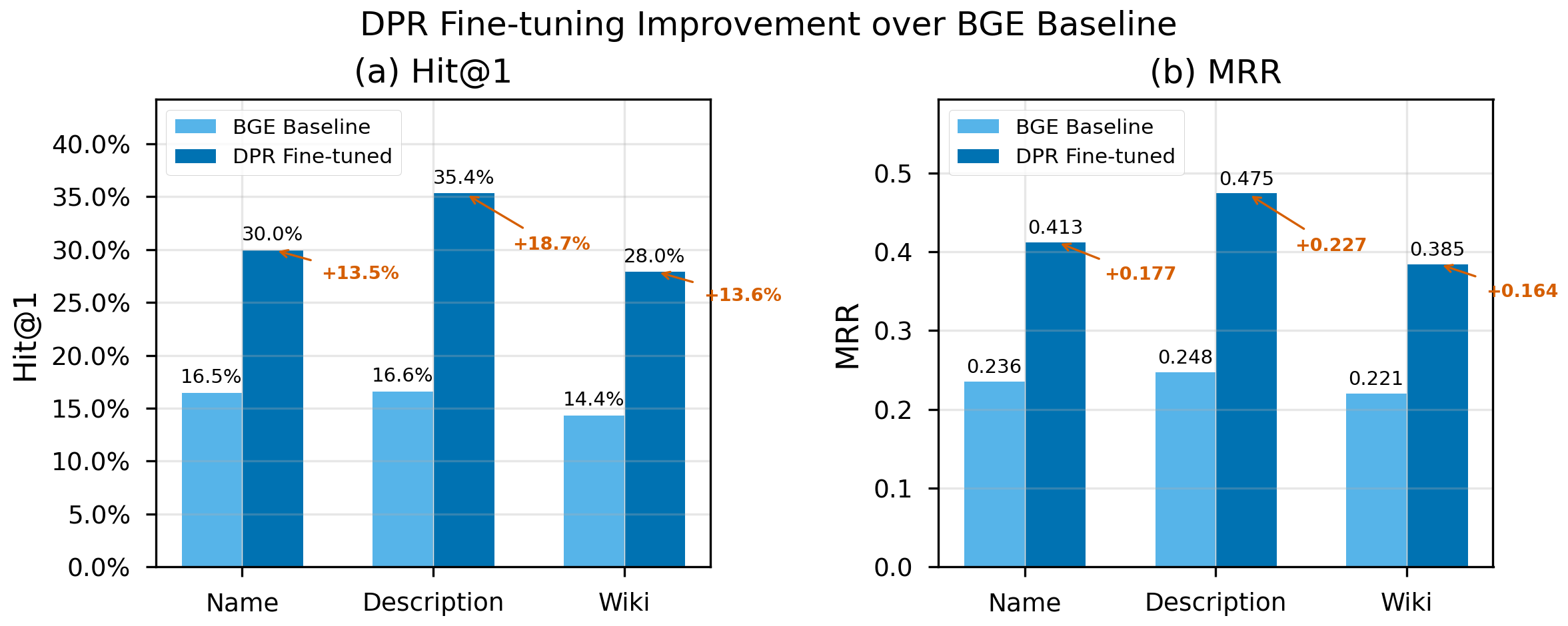
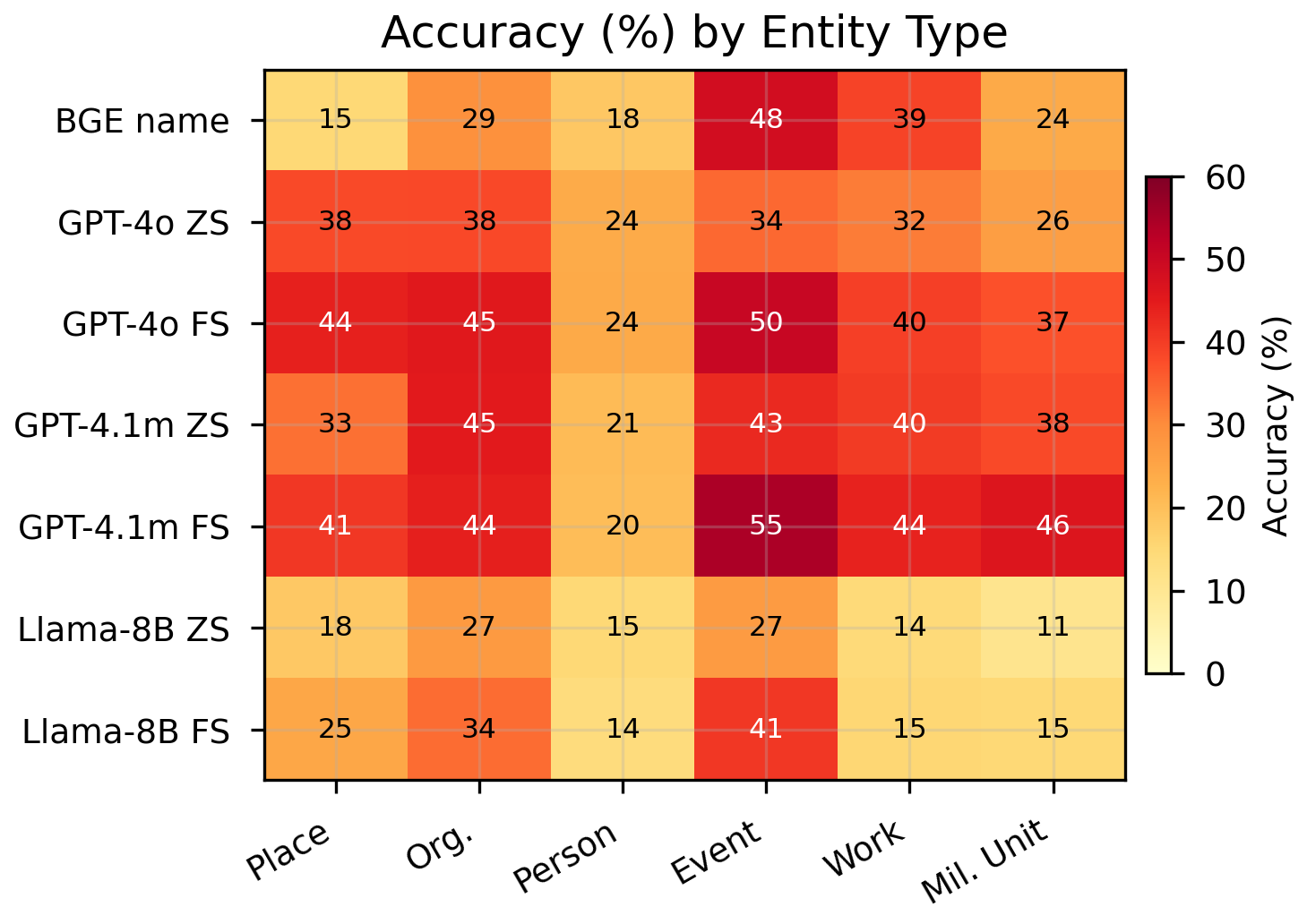
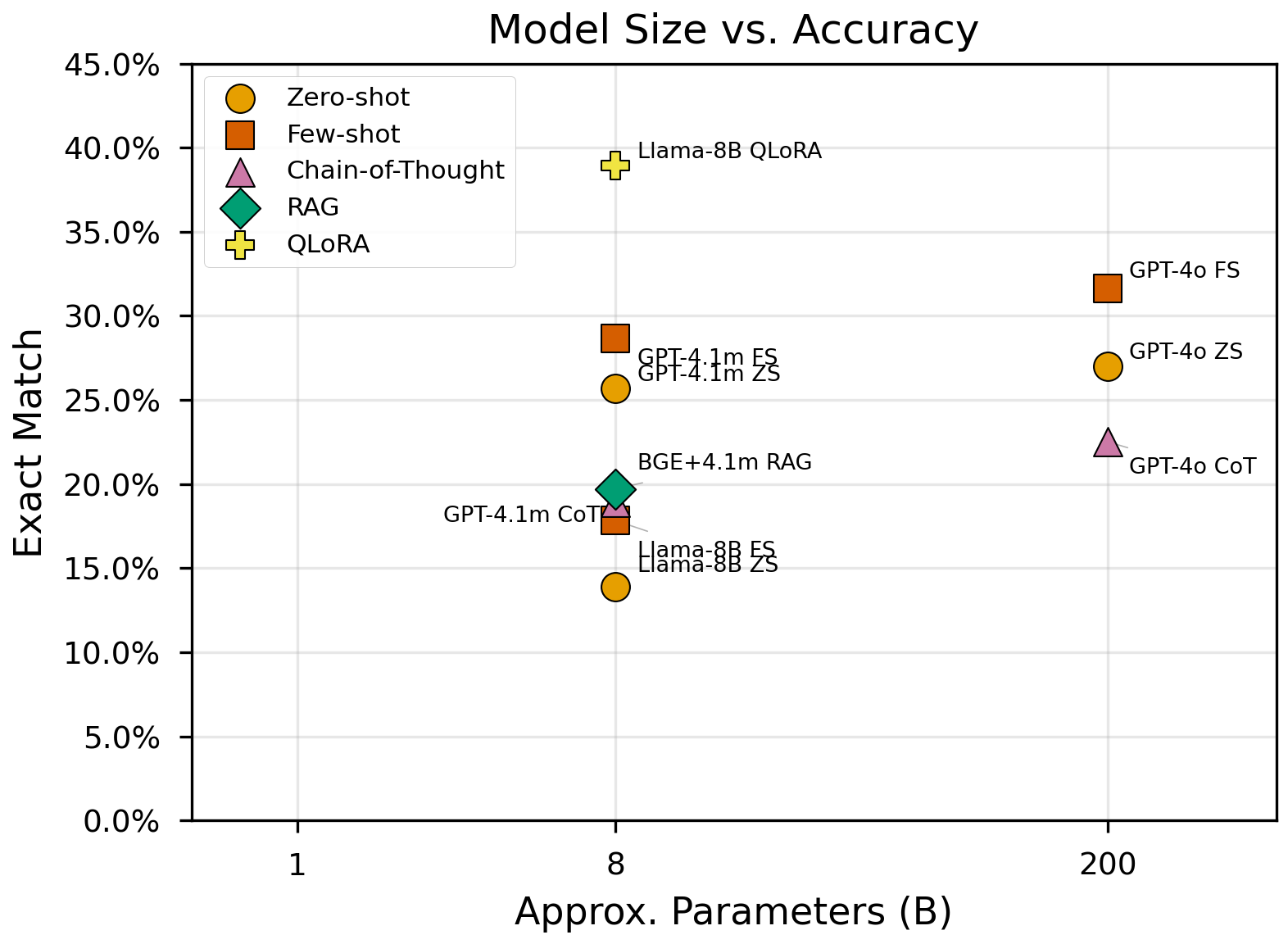
- Comprehensive evaluation. We systematically compare 19 experimental configurations spanning open-world LLM inference (zero-shot, few-shot, chain-of-thought, QLoRA fine-tuning), closed-world dense retrieval (off-the-shelf and DPR fine-tuned), and hybrid RAG, revealing that fine-tuning doubles performance in both paradigms, chain-of-thought reasoning degrades performance on this task, and model scale is the dominant factor in open-world accuracy.
2. Related Work
2.1 Named Entity Recognition
Named Entity Recognition identifies and classifies explicit entity mentions in text. Classical approaches relied on handcrafted features and conditional random fields [1], while modern systems employ deep learning architectures including BiLSTM-CRF [9], transformer-based sequence labeling [10], and large language model prompting [11, 12]. Recent benchmarks such as CoNLL-2003 [13] and MultiCoNER [14] have driven progress across entity types and languages. The W2NER framework [15] unified flat, nested, and discontinuous NER as word-word relation classification, and UniversalNER [16] demonstrated targeted distillation from LLMs for open-domain entity extraction. Despite these advances, all NER formulations assume the target entity appears as an explicit surface form in the input text, an assumption that does not hold for implicit references.
2.2 Entity Linking
Entity Linking resolves textual mentions to entries in a knowledge base. Neural approaches include local attention models [3], bi-encoder architectures such as BLINK [17], autoregressive generation via GENRE [18], and efficient zero-shot systems like ReFinED [19]. Botha et al. [20] extended entity linking to over 100 languages. These systems take an identified mention span as input and rank candidate entities; they cannot operate when no mention span exists. Implicit entity recognition requires generating entity candidates from distributed contextual cues rather than resolving a given span.
2.3 Reminiscence Analysis and NLP
Reminiscence, the structured recall of autobiographical memories, has been studied extensively in psychology and gerontology. Butler [38] first proposed life review as a therapeutic process, and subsequent work established reminiscence therapy as an evidence-based intervention for depression and cognitive decline in older adults [6, 7]. Webster [39] developed the Reminiscence Functions Scale, identifying eight distinct functions of autobiographical memory sharing. Computational approaches to reminiscence have focused primarily on two areas: reminiscence therapy systems and oral history processing. Therapy-oriented systems use conversational agents or social robots to elicit and respond to personal memories [11, 12, 40], while oral history processing addresses transcription, topic segmentation, and search [9, 41]. However, none of these systems address the fundamental challenge of identifying the entities that speakers reference implicitly. Our work bridges this gap by extending implicit entity recognition, previously studied only in short social-media text [21, 22], to the reminiscence domain and providing the first benchmark derived from real reminiscence narratives.
2.4 Implicit and Zero-Mention Entities
Limited prior work has addressed entities that are referenced but not named. Hosseini [21] introduced implicit entity recognition in tweets, constructing a dataset of 3,119 tweets with implicit entity mentions. Hosseini and Bagheri [22] developed learning-to-rank methods for this Twitter dataset. Perera et al. [23] explored implicit entity recognition in clinical documents. The coreference resolution community has studied "zero anaphora" and bridging references [42, 43], where an entity is referenced indirectly through related concepts.
Our work differs from these efforts in five fundamental ways. First, domain and text structure. Tweets are short (under 280 characters), formulaic, and heavily context-dependent on trending topics; clinical notes follow rigid templates. Reminiscence narratives are extended first-person accounts (typically 50 to 200 words per sample) with rich, diffuse contextual cues spanning dates, locations, personal relationships, sensory details, and historical events. Second, non-locality. In tweets, the implicit entity is typically inferable from a single cue or hashtag context. In reminiscence narratives, building on the bridging-anaphora and zero-mention coreference literature [42, 43] that has long noted indirect reference, we operationalize the non-locality property at scale: a formal definition (no contiguous span suffices to identify the entity, yet the union of non-contiguous cues does), a per-sample sentence-ablation diagnostic, and benchmark-scale evidence that this regime causes systematic failures in standard pipelines. Third, scale and diversity. IRC-Bench contains 25,136 samples spanning 12,337 unique Wikidata-linked entities across 11 thematic domains, compared to 3,119 tweet samples in Hosseini [21] covering primarily entertainment and sports entities. Fourth, entity-level evaluation. We introduce entity-level train/test splitting with zero entity overlap, ensuring that models must generalize to entirely unseen entities rather than memorizing entity-specific patterns. Prior benchmarks used random sample-level splits where the same entity could appear in both training and test data. Fifth, comprehensive method comparison. We systematically evaluate 17 configurations spanning four paradigms (generative LLM, dense retrieval, RAG, fine-tuning), whereas prior work evaluated at most two to three approaches on a single paradigm.
2.5 Oral History NLP
Computational analysis of oral histories has received growing attention. Technology-assisted reminiscence systems have been developed for dementia care [7, 8], and AI-driven conversational agents have been explored as companions for elderly users [24, 25]. Digital storytelling platforms combining AI with augmented reality enable communities to preserve personal narratives [26]. However, these systems primarily facilitate memory recall and do not attempt to recover the implicit entities that speakers reference without naming.
2.6 Knowledge-Grounded Question Answering
The closest existing task to implicit entity recognition is knowledge-grounded question answering, where a system must reason over both a text passage and an external knowledge base to produce an answer [27, 28]. Retrieval-augmented generation (RAG) approaches retrieve relevant knowledge base passages and condition generation on them [29, 30]. While implicit entity recognition shares the requirement for external knowledge, it differs in that the "question" is an entire narrative rather than a targeted query, and the answer is always a single entity rather than a free-form text span. Furthermore, implicit entity recognition exhibits the non-locality property: the relevant cues are distributed throughout the passage rather than concentrated near a question token. This structural difference, as we show empirically, causes standard RAG pipelines to underperform direct LLM inference.
2.7 Recent Developments (2022 to 2025)
Since the initial study of implicit entity recognition on social media [21, 22], four related threads have advanced the surrounding state of the art without directly addressing the long-form implicit-mention regime. Entity linking with LLMs. Direct prompting frameworks such as ChatEL [44] and LLM-based context augmentation for long-tail entities [45] reformulate entity linking around LLM reasoning, but both presume an explicit surface mention to resolve. Long-context entity tracking. Recent benchmarks stress-test entity and fact recall across thousands of tokens, including BABILong [46] for reasoning-in-a-haystack and RULER [47] for synthetic needle-in-a-haystack variants. The most directly relevant is NoLiMa [48], which shows that long-context retrieval performance collapses when lexical overlap with the query is removed; this is precisely the regime that IRC-Bench targets at the dataset level, with naturally occurring rather than synthetically removed lexical anchors. Coreference and bridging. The CRAC 2023 shared task [49] codifies bridging-adjacent annotation across multilingual corpora but stops short of zero-mention recognition where no antecedent span exists. Oral history NLP. Speech-technology pipelines for archival audio [50] and LLM-based topical and sentiment annotation of oral-history corpora [51] motivate the downstream entity-grounding task we address, none of these existing efforts attempt entity recovery under implicit reference. IRC-Bench occupies the intersection these threads converge on, long-context, lexically de-coupled, entity-grounded recognition over reminiscence narratives.