1. Introduction
Reminiscence, the act of recalling and sharing personal memories, plays a central role in human social life. In clinical settings, reminiscence therapy reduces depression in older adults [6], while in archival contexts, recorded reminiscences preserve cultural knowledge [7]. A defining characteristic of reminiscence narratives is that speakers reference people, places, and events through contextual cues rather than explicit naming, trusting the listener to fill in the gaps. This implicit referencing creates a fundamental challenge for automated systems that seek to index, search, or analyze these narratives.
Consider the following passage from a Japanese American reminiscence:
Entity-Grounded Narrative (EGN)
"The attack on Pearl Harbor was the event that changed everything for Japanese Americans like me. After December 7, 1941, suspicion and hatred grew, and we were treated as enemy aliens despite being American citizens. It was because of Pearl Harbor that the government issued Executive Order 9066 and started the forced relocation."
Entity-Elided Narrative (EEN)
"The surprise attack on a naval base in Hawaii was the event that changed everything for Japanese Americans like me. After December 7, 1941, suspicion and hatred grew, and we were treated as enemy aliens despite being American citizens. It was because of that attack that the government issued an order and started the forced relocation."
Gold entity: Attack on Pearl Harbor (Q52418) | Cues: December 7, 1941; naval base in Hawaii; Executive Order 9066; forced relocation
A human reader identifies the Attack on Pearl Harbor from the constellation of cues: the date, the Hawaiian naval base, the executive order, the internment. No single phrase names the entity; recognition depends on integrating knowledge distributed across the entire passage. This phenomenon falls between existing NLP tasks. Named Entity Recognition (NER) identifies explicit spans [1, 2]. Entity Linking (EL) resolves those spans to knowledge base entries [3, 4]. Coreference resolution requires at least one explicit mention as antecedent [5]. In implicit entity references, the entity is never named; there is no span to extract, no mention to link, no antecedent to resolve.
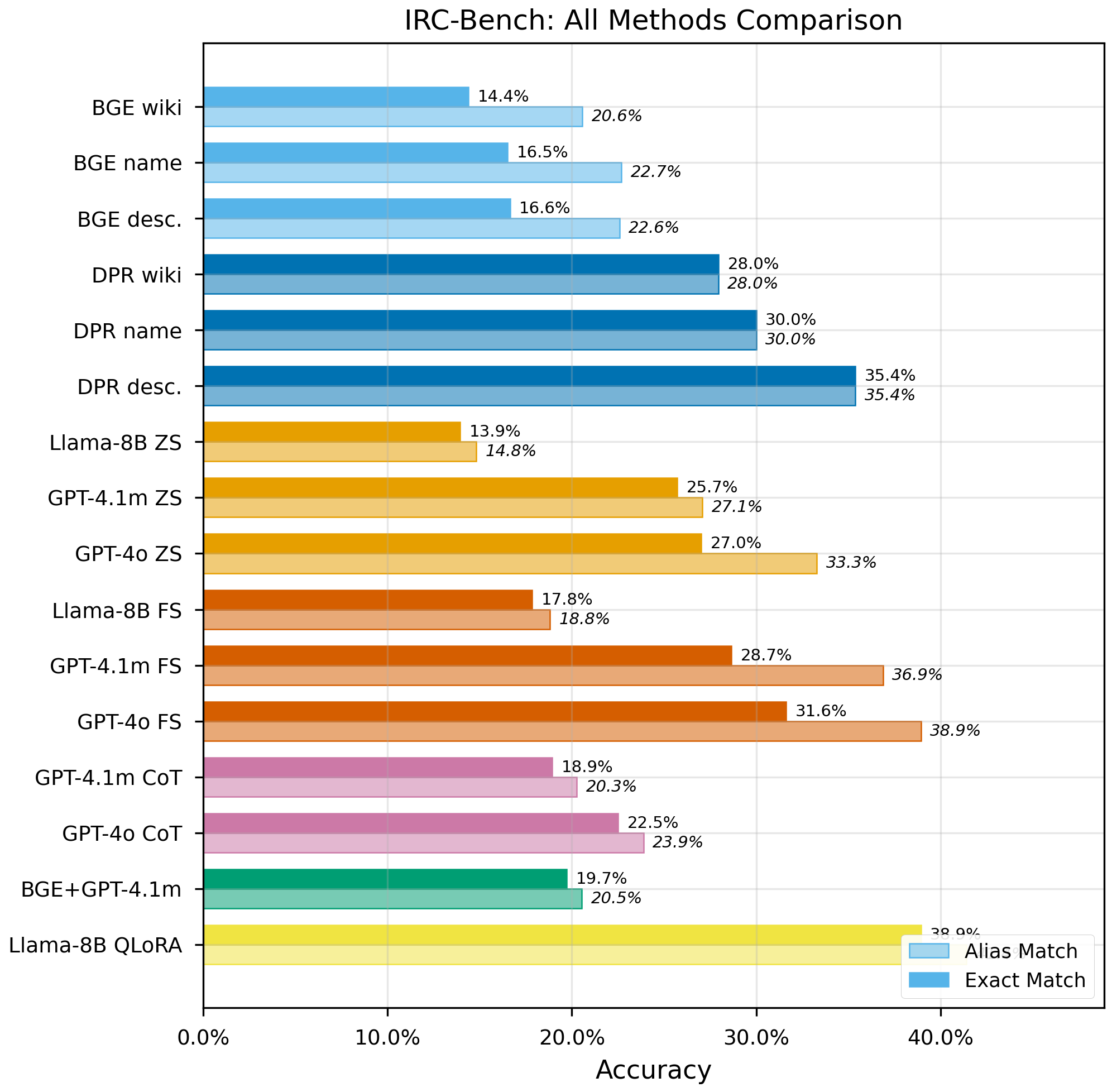
Our contributions are: (1) We extend implicit entity recognition from tweets [17, 18] to long-form reminiscence narratives and formalize the non-locality property of implicit references. (2) We release IRC-Bench, a benchmark of 25,136 samples from 12,337 Wikidata-linked entities across 1,994 transcripts, with entity-level train/dev/test splits ensuring zero entity overlap. (3) We systematically compare 19 configurations spanning four paradigms (generative LLM, dense retrieval, RAG, fine-tuning), revealing that fine-tuning doubles performance, chain-of-thought reasoning degrades accuracy, and model scale is the dominant factor in open-world performance.
2. Related Work
Limited prior work has addressed entities that are referenced but never named. Hosseini [17] introduced implicit entity recognition in tweets, constructing a dataset of 3,119 tweets. Hosseini and Bagheri [18] developed learning-to-rank methods for this Twitter dataset. Perera et al. [19] explored implicit entity recognition in clinical documents. The coreference resolution community has studied "zero anaphora" and bridging references [20, 21], where entities are referenced indirectly. Computational approaches to reminiscence have focused on therapy systems using conversational agents [8, 9] and oral history processing for transcription and search [10, 11]; none address the challenge of identifying implicitly referenced entities.
Our work differs from prior formulations in several ways. First, reminiscence narratives are extended first-person accounts (50 to 200 words per sample) with rich, diffuse contextual cues, unlike short tweets or templated clinical notes. Second, we formalize and empirically demonstrate the non-locality property: recognition requires integrating multiple non-contiguous cues. Third, IRC-Bench contains 25,136 samples spanning 12,337 entities across 11 domains, compared to 3,119 tweet samples in Hosseini [17]. Fourth, we introduce entity-level splitting with zero overlap, ensuring models must generalize to unseen entities. Fifth, we evaluate 19 configurations spanning four paradigms, whereas prior work evaluated at most two to three approaches.
3. Dataset Construction
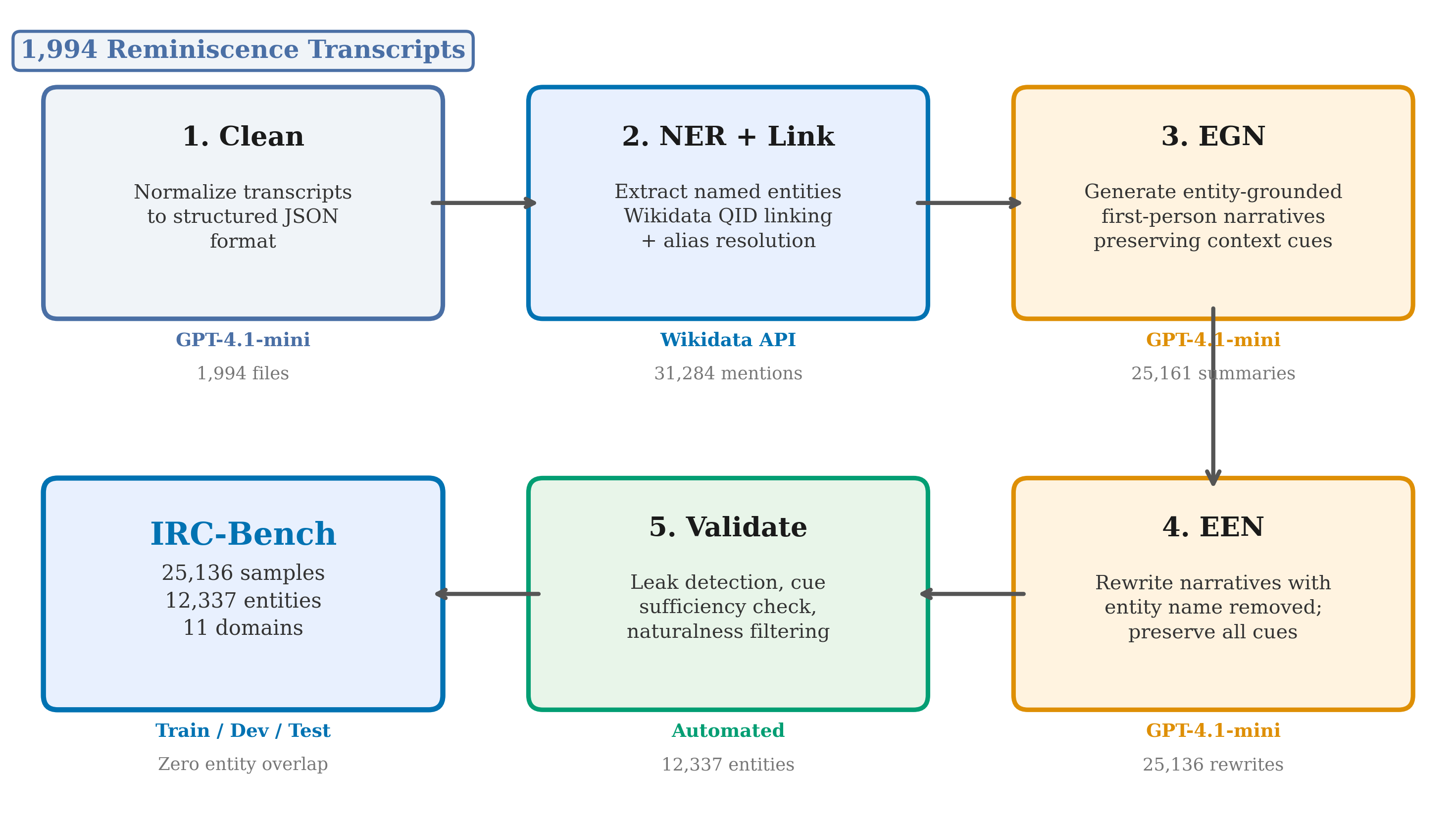
IRC-Bench is constructed through a four-stage automated pipeline that transforms oral history transcripts into implicit entity recognition samples. The pipeline leverages GPT-4.1-mini for entity extraction, summary generation, and implicit rewriting, producing 25,136 benchmark samples spanning 12,337 unique entities from 1,994 transcripts across 11 thematic domains (Table 1).
Stage 1: Transcript Cleaning. Raw oral history transcripts are cleaned and converted to structured JSON, preserving the first-person narrative voice. Stage 2: NER. GPT-4.1-mini identifies named entities of seven types (Place, Organization, Person, Event, Work, Military Unit, Other), linking each to Wikidata. This produces 31,284 mentions across 1,752 files. Stage 3: Explicit Summary. For each (transcript, entity) pair, GPT-4.1-mini generates a first-person narrative preserving contextual cues. Stage 4: Implicit Rewriting. Each summary is rewritten to remove all direct entity mentions while preserving contextual cues, producing the final 25,136 implicit samples.