Acting on the Unseen: Communication-Free Collaborative Filtering for Decentralized Multi-Robot Task Allocation
Alexander Apartsina, Yigal Meshulamb, Yehudit Apersteinb,∗
aHolon Institute of Technology, Holon, Israel. bAfeka Tel Aviv Academic College of Engineering, Tel Aviv, Israel. ∗Corresponding author.
- Prior-free, communication-free MRTA under partial, privately-noisy observation.
- Decentralized online collaborative filtering acts on never-attempted tasks.
- Categorical separation over structure-free learning: proven and validated.
- A positive scaling law: per-robot competence on unseen tasks rises with team size.
- Robust to masking and to the rank guess; leads clustering, batch, and Bayesian low-rank baselines with no cluster structure to exploit.
Keywords: multi-robot task allocation; decentralized learning; collaborative filtering; low-rank matrix completion; communication-free coordination; swarm robotics.
1. Introduction
Consider a team of autonomous robots, for example aerial vehicles, that must repeatedly decide which task to engage: which area to inspect, which target to service, which sensor reading to pursue. Whether a given robot does well on a given task depends on a match between the robot's capabilities (sensor modalities, payload, effector type, endurance, remaining consumables) and the task's requirements. This capability-requirement view is the basis of trait-based task allocation [1], and the match is typically governed by only a few underlying factors, so the full robot $\times$ task reward is low-rank. That a few factors suffice is borne out in practice: learned low-dimensional capability and task-requirement models predict real robotic task performance to within a few percent [2], and the analogous two-sided affinity matrix is well captured by a few dominant dimensions in large matching datasets [3].
Most multi-robot task allocation (MRTA) methods obtain coordination from at least one of three resources: explicit communication (auctions, consensus, message-passing), known task models or utilities, or a central coordinator / centralized training. In many real deployments none of these is available: communication is jammed, bandwidth-limited, or deliberately withheld for stealth; the task structure is unknown a priori; and there is no coordinator. What a robot can often still do is passively sense some of what its teammates are doing and how it turned out, imperfectly, at a distance, and differently from every other robot. This is documented, not hypothetical: fielded drone swarms already coordinate from purely onboard, range- and line-of-sight-limited mutual perception with no inter-robot messaging [4,5], and heterogeneous teams routinely operate under denied or degraded communication, as across the DARPA Subterranean Challenge [6,7]. This is the regime we formalize and solve: a robot observes a partial (range-limited) and privately-noisy slice of a public outcome stream, never the same slice as a teammate.
The technical crux is generalization to the unseen. There are far more tasks than rounds ($n \gg T$), so each robot personally attempts only a vanishing fraction of tasks. A learner that estimates each task only from its own attempts (a structure-free learner: independent per-task bandits, tabular value tables) has, on any task it never attempted, nothing better than the prior mean, the error floor, which dominates exactly because tasks outnumber rounds. The opportunity is that the shared low-rank structure links tasks: outcomes a robot observes teammates obtain (even noisily and partially) constrain that structure, and a few observations then determine the robot's reward on tasks it has never touched. We show a single, simple estimator turns this opportunity into a categorical capability.
The gap. To our knowledge no prior method targets this cell. Every established paradigm relaxes at least one of its defining constraints (no prior knowledge, no communication, decentralized decisions, and partial and privately-noisy observation) by assuming communication, known utilities/traits, a coordinator or centralized training, or clean/shared observation (Section 2, Table 1). The regime is not exotic: it is the default when communication is jammed, bandwidth-limited, or withheld for stealth, and when task structure must be discovered in the field. We close it.
Relation to collaborative filtering. Low-rank collaborative filtering is itself classical; our contribution is not the estimator but the demonstration, with theory, that it works at all in this regime, fully decentralized, communication-free, and under a persistent, per-observer-private observation mask where standard uniform-sampling completion guarantees do not apply, together with the recovery condition that says exactly when it works and the collective-speedup law that says why a swarm helps. The categorical floor against structure-free learning, the decentralized recovery condition under a structured private mask, and the value-of-broadcast / positive-scaling results are, to our knowledge, new.
Contributions.
- We formalize and name Zero-Knowledge MRTA (ZK-MRTA): communication-free MRTA under partial, privately-noisy observation and zero prior knowledge, a most-restrictive but practically common regime that prior MRTA and decentralized-learning work does not address (Section 2, Table 1).
- We propose SwarmCF, a decentralized, online, low-rank collaborative filter that each robot runs over the passive broadcast, with a constant-time fold-in (an $O(\hat d^3)$ ridge solve in the guessed rank $\hat d$, independent of the task count $n$; Section 4) that lets it act on unseen tasks and onboard new tasks.
- We prove the advantage is categorical: a structure-free learner is at the error floor on unseen pairs and the broadcast is provably uninformative to it, whereas SwarmCF attains a per-robot sample complexity of $\Theta(d)$ versus $\Theta(n)$, with a matching anytime separation under task scarcity (Section 5).
- We give a deterministic condition under which decentralized recovery of the shared structure from the privately-masked broadcast is exact, with a coverage-time bound that improves as the team grows, and validate the condition empirically (Section 5, Appendix A).
- We quantify the value of the broadcast, a positive scaling law (per-robot competence rises with team size), and a strong masking-robustness and anytime profile among low-rank methods under limited observability (the online anytime lead holds at the body's size-$c$ menu and narrows under the unrestricted all-tasks menu, Appendix E), and we measure the cost of communication-free operation against a centralized full-communication ceiling, where the residual gap is dominated by estimation under the masked broadcast rather than coordination (Section 6.4); and we show the advantage persists under capacity-1 contention (Section 6.5) and in a robotics-grounded instance with heterogeneous sensing traits and a range-limited line-of-sight mask (Section 6.7), including a physically assembled detection reward whose low rank is emergent rather than assumed (Appendix E).
- We release LatentSwarm, an open, modular Python package for ZK-MRTA, covering the masked-broadcast setting used for our headline results and its capacity-1 contention extension; with it we show the separation survives contention and that SwarmCF's heterogeneous per-robot models implicitly de-conflict where structure-free learners instead collide, isolating communication-free de-confliction as the main open problem (Section 6.5, Appendix D).
2. Related work
Swarm robotics seeks collective competence from simple local rules [8,9], and coverage and patrolling control coordinate where robots move [10]; we instead address which task each robot should engage when the capability-to-task match is unknown and there is no communication.
Multi-robot task allocation. The taxonomies of Gerkey and Matarić [11], Korsah et al. [12], and Nunes et al. [13] organize MRTA by single/multi-task robots, single/multi-robot tasks, and instantaneous/time-extended assignment with interrelated utilities and temporal constraints. Classical solvers, market and auction mechanisms [14], consensus-based bundle algorithms (CBBA) [15], and distributed constraint optimization achieve coordination through communication and assume known task utilities or costs (surveys: [16]); even work that explicitly limits communication still relies on auctions and messages [17], and a recent review underscores how central communication remains to multi-robot systems [18]. Trait-based and heterogeneity-aware MRTA [1,19,20] matches robot capability vectors to task requirement vectors, but takes the traits as given. Our setting keeps the trait/low-rank view but makes the traits unknown and learned online, with neither communication nor known utilities; recent surveys [21] document the rapid growth of learning-based MRTA, but the prior-free, communication-free regime we study remains unaddressed.
Decentralized and learning-based coordination. Communication-free multiplayer bandits (musical chairs [22], SIC-MMAB [23], game-of-thrones [24]) break symmetry without messages but are structure-free (per-arm), so they cannot generalize to unseen arms. Cooperative multi-agent RL (CTDE: MAPPO [25], QMIX [26], VDN [27], MADDPG [28]) and learned-communication methods (CommNet [29], TarMAC [30], DIAL [31]) rely on centralized training or message passing; recent learning-based decentralized assignment (graph neural networks for goal assignment [32] and scheduling [33]) likewise presumes communication or centralized training. Federated and gossip collaborative filtering [34], and federated learning more broadly [35], coordinate by exchanging model parameters or gradients; we exchange nothing but a passively-sensed outcome stream. Decentralized partially-observable control (Dec-POMDPs [36]) addresses long-horizon coordination under shared latent-state dynamics; our rounds are one-shot offered-set choices with no shared state, so the challenge is cross-task generalization from a privately-masked stream rather than long-horizon credit assignment.
Low-rank estimation and bandits. Matrix completion gives centralized recovery guarantees under (near-)uniform sampling [37,38,39,40], with practical factorization estimators (matrix factorization [41], Bayesian PMF [42], soft-impute [43], implicit-feedback ALS [44], ranking CF [45]); low-rank and bilinear bandits (explore-then-spectral [46], bilinear [47], generalized-linear [48], clustering-of-bandits [49]) are centralized and/or phase-structured. Decentralized matrix completion [50] distributes the factorization across nodes but still exchanges factors or residuals over a connected communication graph; we forbid all such exchange and recover from passive observation alone. We make estimation decentralized, online, broadcast-only, and robust to a structured (non-uniform) per-robot observation mask, with the unseen-pair error floor turning the gap into a categorical, rather than constant-factor, separation.
Table 1 places the major paradigms on the four axes that define our problem; each established family relaxes at least one axis we hold fixed, and our cell, low-rank with only a guessed rank, no communication, decentralized, masked and noisy, is the one left open.
Table 1. Established paradigms versus our regime across prior knowledge, communication (with decision locus folded in), and observation; the final column names the constraint each relaxes (ours relaxes none).
| Paradigm | Prior knowledge | Communication (and decision locus) | Observation | Constraint it relaxes vs. ours |
|---|---|---|---|---|
| Auction / consensus / DCOP MRTA [14,15] | task utilities or costs | message-passing | full task info | needs communication and known utilities |
| Cooperative MARL (CTDE) [25,26] | none (learned) | central training or messages (decentralized exec.) | full (in training) | needs a central critic or messages |
| No-communication multiplayer bandits [22,23] | none (per-arm) | none | own pulls + collisions | structure-free: no unseen generalization |
| Low-rank completion / bandits [37,46] | low-rank | centralized | partial (uniform) | centralized and/or explore-then-commit |
| Federated / gossip CF [34,35] | low-rank | parameter exchange | partial | shares parameters, not a passive stream |
| Trait-based MRTA [1,20] | known traits | varies | full | traits given, not learned |
| Ours: ZK-MRTA (this paper) | low-rank, guessed rank only | none (passive sensing); decentralized | masked + per-observer noisy | none: the open cell (most constrained) |
3. Problem setting: Zero-Knowledge MRTA (ZK-MRTA)
(The term “zero-knowledge” here denotes the absence of any prior task knowledge, no task models and not even the latent rank; it is unrelated to the cryptographic notion of zero-knowledge proofs.)
Reward. A team of $m$ robots faces $n$ tasks. Robot $i$ has a hidden capability vector $p_i\in\mathbb{R}^d$ and task $j$ a hidden requirement vector $u_j\in\mathbb{R}^d$; the expected reward of robot $i$ engaging task $j$ is their inner product$$ R_{ij} \;=\; \langle p_i, u_j\rangle, \qquad R = P U^\top \in \mathbb{R}^{m\times n},\ \operatorname{rank}(R)=d \ll \min(m,n). \tag{1} $$The low rank $d$ encodes that only a few traits govern fit. The team does not know $P$, $U$, or even $d$ (it uses a guessed rank $\hat d$, drawn at random per run, to which the method is robust; Figure 8). We take the reward in normalized form, scaling the latent traits so that $R_{ij}$ is bounded and zero-mean across tasks; this is the bounded, normalized reward referenced by Proposition 1. Zero-mean makes the no-information prior-mean predictor the correct control against which the categorical floor is measured; the degenerate $d=1$ case, where a shared popularity/bias baseline already suffices, is treated in Section 7 (Scope of the advantage).
Interaction. Each round $t=1,\dots,T$ every robot $i$ is offered a menu $S_{it}\subseteq[n]$ of tasks (the model permits the full menu of all $n$ tasks; to control scarcity the body experiments offer a uniform random size-$c$ subset, $c=20$, with the all-tasks menu $c=n$ studied in Appendix E), selects one $a_{it}\in S_{it}$, engages it, and earns $R_{i,a_{it}}$. The operating regime is task-scarce: $n \gg T$, so each robot personally engages only $O(T)$ of the $n$ tasks.
The observation channel (central to the setting). There is no communication. Each robot instead passively senses a public stream of engagement outcomes, but only partially and noisily, and privately: (persistent partial visibility) robot $i$ observes teammate $k$'s engagements only if $M_{ik}=1$, where $M_{ik}\sim\mathrm{Bernoulli}(\rho)$ is fixed for the whole mission ($M_{ii}=1$); (private per-observer noise) when $i$ observes the outcome of action $a_{kt}$ it reads $R_{k,a_{kt}}+\eta_{ikt}$ with $\eta_{ikt}\sim\mathcal N(0,\sigma^2)$ drawn independently per observer, so the same action is read differently by different robots. A robot reads its own engaged outcome with a smaller own-observation noise $\sigma_{\mathrm{own}}<\sigma$ (Section 6 uses $\sigma_{\mathrm{own}}=0.1$ and broadcast noise $\sigma=\sigma_{\mathrm{obs}}=0.3$). No robot ever sees the clean stream, and no two robots see the same stream. We take this persistent mask as the primary case: an i.i.d., per-round mask reduces to standard uniform sampling, so the persistent (structured) mask is the harder regime where our recovery condition (Theorem 2) applies; the released suite supports both, and Appendix E confirms the headline results are unchanged under the i.i.d. mask.
This channel is the formal counterpart of physical sensing: a robot perceives a teammate's engagement and its outcome only when the teammate is within range (the persistent partial mask) and reads it with a fidelity that degrades with distance and with its own sensor (the per-observer noise), so it is physically realizable rather than a convenient abstraction: onboard, range-limited mutual perception without communication already drives real drone swarms [4,5]. Concretely, a robot can often assess a teammate's outcome by direct observation (for example, seeing whether a surveilled area was in fact covered, or whether a serviced target stopped emitting) without any message from the teammate; where only the teammate's action (which task it engaged), and not its scalar outcome, is observable, an action/choice channel is the natural fallback, which we develop in a follow-up. It is strictly weaker than the shared, clean broadcast usually assumed, and it makes decentralization real: persistent blind spots give every robot a permanently different view, and the private per-observer noise means even commonly-visible outcomes are read differently by each robot, so there is no shared, clean signal to average toward agreement and the robots cannot converge to a common model by symmetry. Figure 1 illustrates the setting.
Objective and metric. We measure decision quality by the normalized skill (a Murphy skill score [51] / normalized return),$$ \mathrm{skill} \;=\; \frac{\text{earned} - \text{random}}{\text{oracle} - \text{random}}, \tag{2} $$where for an offered set the oracle picks $\arg\max_{j\in S}R_{ij}$ and random picks uniformly; skill $=0$ is the no-information floor and $1$ is omniscient (a policy worse than random scores below $0$). We report unseen-pair skill (restricted to tasks the robot never engaged, the generalization test), and the anytime (cumulative-reward) skill over the mission.
4. Method: SwarmCF
Each robot independently maintains low-rank factor estimates $\hat P\in\mathbb{R}^{m\times\hat d}$, $\hat U\in\mathbb{R}^{n\times\hat d}$ and updates them online from whatever it senses, using noise-weighted alternating least squares (weighted ridge ALS [40,44], a standard estimator for low-rank completion) on the observed entries. The key design choice for masking-robustness: an unobserved entry receives zero weight, never an imputed zero value. The robot then acts greedily (with a small $\varepsilon$ for exploration) on its completed reward row, which is defined for every task, including ones it never engaged.
New-task onboarding (fold-in [52]). Because the swarm already holds the robot-factor basis, a new task $j^\star$ is absorbed without retraining: its hidden vector is the ridge least-squares solution of its few observed engagements against the corresponding known robot factors, an $O(\hat d^3)$ computation, after which every robot can score $j^\star$. The same fold-in lets a robot predict any unseen pair once it has recovered the basis (Algorithm 2, Appendix B). A new robot is different: it arrives with no memory, and with no communication it cannot be handed the basis, so it must first recover the task factors from the passive broadcast (the coverage time of Theorem 2) and only then fold in its own $\ge\hat d$ engagements; its onboarding is bounded by recovery, not by the $O(\hat d)$ fold-in.
What SwarmCF does and does not assume. It is fully decentralized (one estimator per robot, no shared state), communication-free (it only reads the passive stream), and prior-free beyond a guessed rank $\hat d$ (which it does not need to be exact, and which can itself be removed by a rank-adaptive variant we defer to follow-up work). It does not assume the noise level is known: uniform weighting suffices and is what we use for the headline results.
Computational cost. SwarmCF is light enough to run on each robot. Acting is $O(c\hat d)$ per round (score the offered set). A periodic refit is a few alternating ridge sweeps, each solving $O(m+n)$ linear systems of size $\hat d\times\hat d$, i.e. $O\big(\text{sweeps}\cdot(m+n)\hat d^3 + |\Omega_i|\hat d^2\big)$ time, with $O((m+n)\hat d + |\Omega_i|)$ memory; since $\hat d$ is a small guessed rank this is small for swarm-scale $m,n$. Folding a new task (or an unseen pair) into the recovered basis is a single $O(\hat d^3)$ ridge solve. There is no inter-robot computation: each robot updates only its own factors and reads the passive stream.
5. Theory: the categorical separation from structure-free learning
We formalize the separation between structure-free learning and SwarmCF, give the per-robot sample complexity, and state the conditions under which decentralized recovery from the masked broadcast succeeds. Proofs are in Appendix A; here we give the statements and the intuition. We use the term Proposition for a self-contained structural fact, Lemma for an intermediate result that a theorem builds on, and Theorem for a main separation or recovery guarantee. A learner is structure-free if its estimate of $R_{ij}$ depends only on robot $i$'s own past engagements of task $j$ and equals a fixed prior on any task it never engaged (the per-arm class: Independent-UCB, tabular).
Proposition 1, Lemma 1, and Theorem 1 make the separation categorical (zero versus nonzero) and operational (it shows up in reward earned while learning). The zero side is by construction: a structure-free learner is defined to fall back on the prior off its own engagements, so its floor on unseen pairs characterizes that class (independent per-task bandits, tabular value tables) rather than reflecting a contest; the weight of the claim rests on the nonzero side, that SwarmCF can in fact recover and act, which is not automatic. Since Lemma 1 still assumes $U$ is known, the remaining question, the central problem of the decentralized setting, is whether each robot can recover the shared structure from its own privately-masked, noisy stream. Because the mask is over robot pairs, robot $i$'s observations form a structured (non-uniform) sub-sample, exactly where off-the-shelf uniform-sampling completion does not apply. We give a deterministic condition instead.
Theorem 2 turns the previously-cited completion step into a self-contained, checkable condition: a pair $(i,j)$ is predicted exactly when robot $i$'s own factor lies in the span of the visible teammates that engaged $j$, and not otherwise, with the threshold reached faster the larger the team. The coverage condition needs $\rho m\gt d$ on average, so at very low broadcast ($\rho m\lt d$, e.g. $\rho=0.1$ with $m=30,d=5$) recovery is only partial and the low-$\rho$ skill in Figure 2 is correspondingly reduced. Appendix A validates it directly: on the actual observation patterns the swarm produces, reconstruction error collapses from the prior floor to (numerically) zero exactly at the spanning threshold.
Theorems 2-3 are, to our knowledge, the first results that pin decentralized low-rank recovery from a persistent, private, per-robot mask to an explicit condition and tie its rate to team size; they are what make the categorical claim self-contained rather than imported from centralized theory. Full proofs are given in Appendix A.
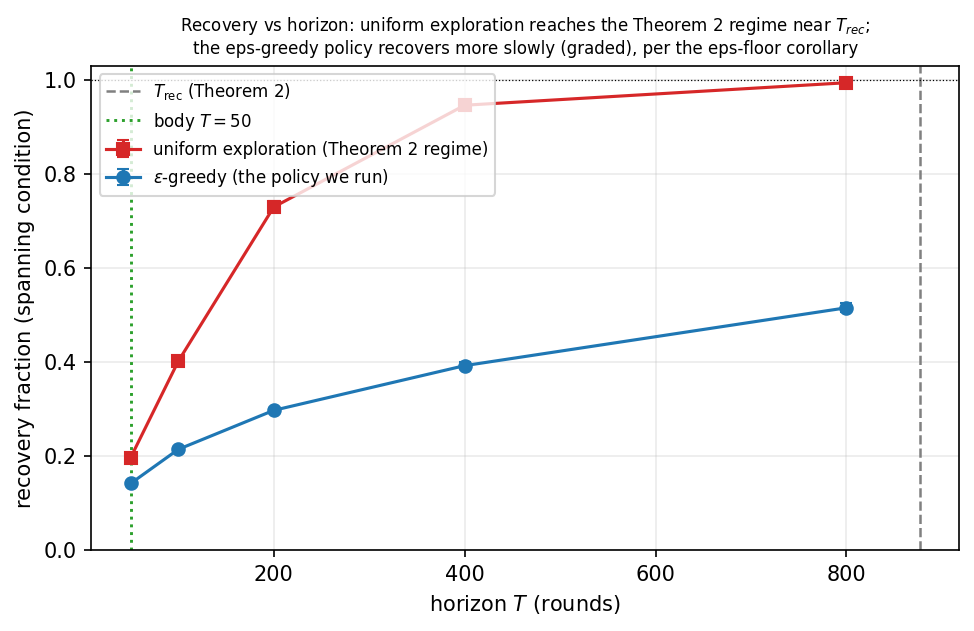
Relation to the experiments. Theorems 1-3 are worst-case sufficient guarantees: they certify when recovery and the categorical gap are achievable and how the rate improves with team size, and Appendix A confirms the governing spanning condition directly on the swarm's actual coverage. SwarmCF then realizes the advantage sample-efficiently: acting well requires only correct ranking of each offered set, not exact reconstruction of the entire row, and recovery is graded in the local spanning rank (Appendix A), so a robot scores a task accurately as soon as a few similar teammates have engaged it. The headline horizon $T=50$ is in fact well below the worst-case full-recovery time $T_{\mathrm{rec}}=O\!\big(\tfrac{nd}{\rho m}\log n\big)$, which is numerically several hundred rounds at the headline $n=240,d=5,m=30,\rho=0.25$; the method nonetheless reaches strong skill within $T=50$ because partial, graded recovery is enough to rank well. The theory thus establishes feasibility and the team-size scaling of full recovery, while the experiments operate in the earlier graded-spanning regime (Appendix A), not at the full-recovery threshold. The $\varepsilon$-floor corollary of Appendix A makes the rate finite (not merely asymptotic) for the exploiting policy we actually run, and the recovery-versus-horizon sweep (Appendix E, Figure 13) confirms the picture directly: under the non-adaptive exploration the theorem assumes, recovery reaches $\approx 0.99$ near $T_{\mathrm{rec}}$, while at the body's $T=50$ only $\approx 14\%$ of pairs are formally recovered yet ranking is already accurate.
6. Experiments
Setup. Unless noted, $m=30$ robots, $n=240$ tasks, true rank $d=5$, guessed rank $\hat d$ drawn at random in $[d,2d]$ per run (no method is given the true rank; this range over-specifies and so never under-ranks, with Figure 8 separately showing graceful degradation when $\hat d
How to read the comparison. The setting is new, so this is a controlled sweep across the low-rank design space against the external structure-free paradigm and full-information ceilings, not a contest of rival systems: SwarmCF is ours; the structure-free learners (Independent-UCB, a per-arm UCB1 [53]; tabular) are the external paradigm; standard low-rank estimators (MF-SGD, spectral, Bayesian completion) are adapted to the setting; the Oracle and a centralized full-communication matcher are upper bounds, not competitors. Communication-based methods (auctions/CBBA, CTDE, federated/gossip CF) are inadmissible by the problem definition: a gossip or decentralized matrix-completion method, throttled to the communication-free passive budget, reduces to per-robot local low-rank completion, exactly our MF-SGD and PTF (SwarmCF is its online-ALS member); and a Gang-of-Bandits method needs a prior similarity graph, so its data-driven successor CLUB is the admissible clustered-bandit. Two further structure-sharing baselines, memory-based kNN-CF and convex nuclear-norm SoftImpute, are evaluated in Appendix E. In our harness every method runs decentralized and communication-free (one estimator per robot), differing only in the update rule; Table 3 (Appendix C) gives each method's operating profile.
6.1 The categorical separation and masking robustness
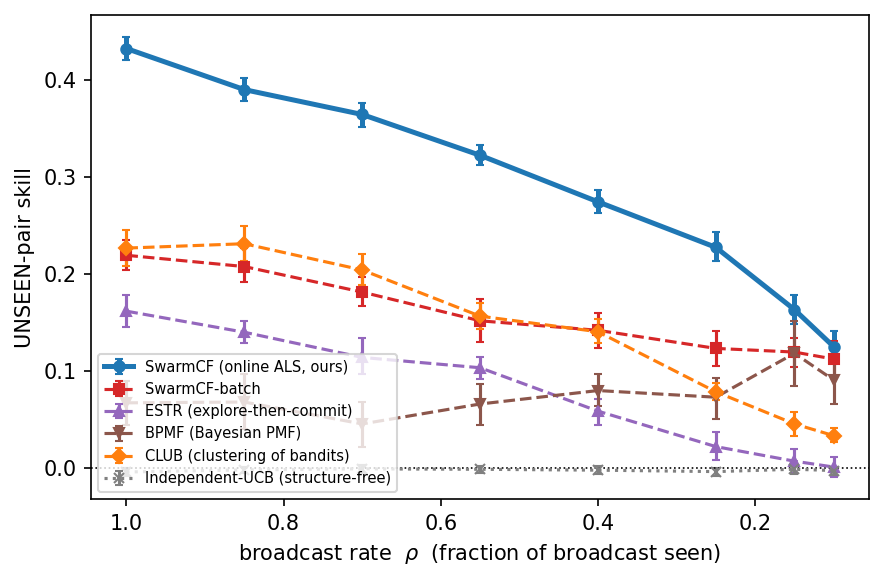
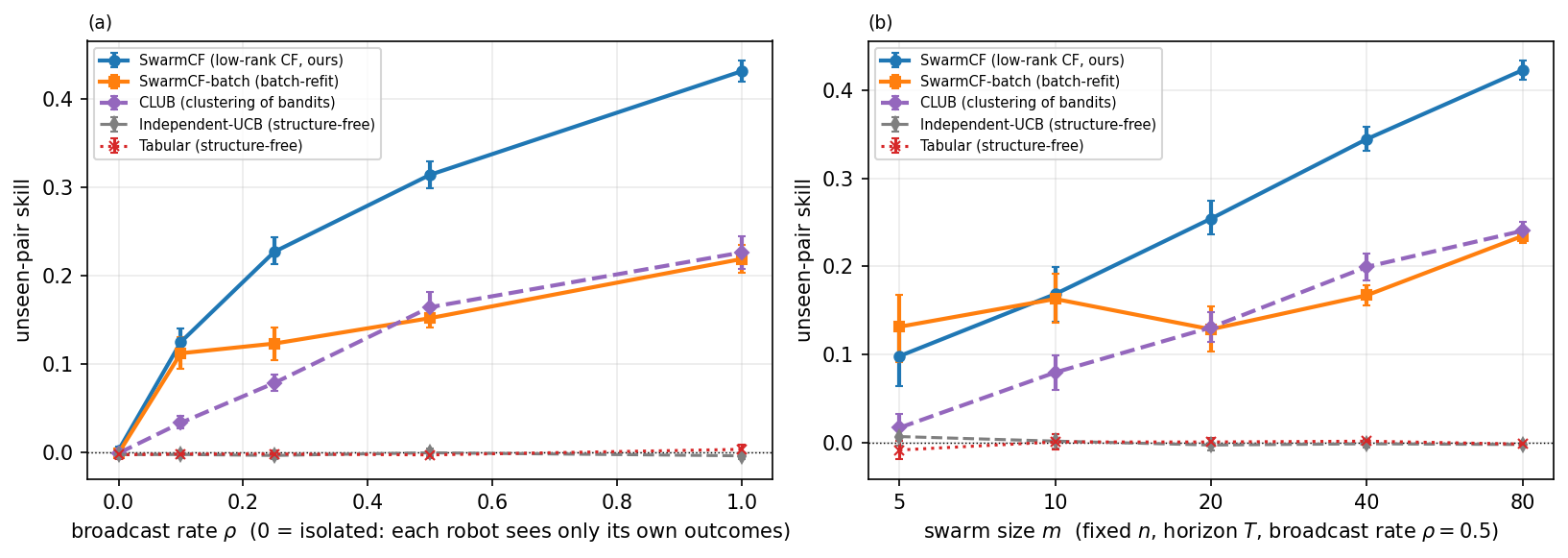
Figure 2 sweeps the broadcast rate $\rho$ and reports unseen-pair skill. SwarmCF acts well on tasks it never engaged at every broadcast rate, while the structure-free learners sit at the floor ($\approx 0$) by construction, the categorical separation of Proposition 1 and Lemma 1. Among low-rank methods, SwarmCF's online updates stay robust as the broadcast is masked, whereas the batch variant SwarmCF-batch (which imputes unobserved entries) decays as observation becomes partial. With continuous (no-type) latent traits SwarmCF leads at every broadcast rate, and its margin over the batch variant is largest under heavy masking, the operationally relevant regime.
6.2 The operational (anytime) separation
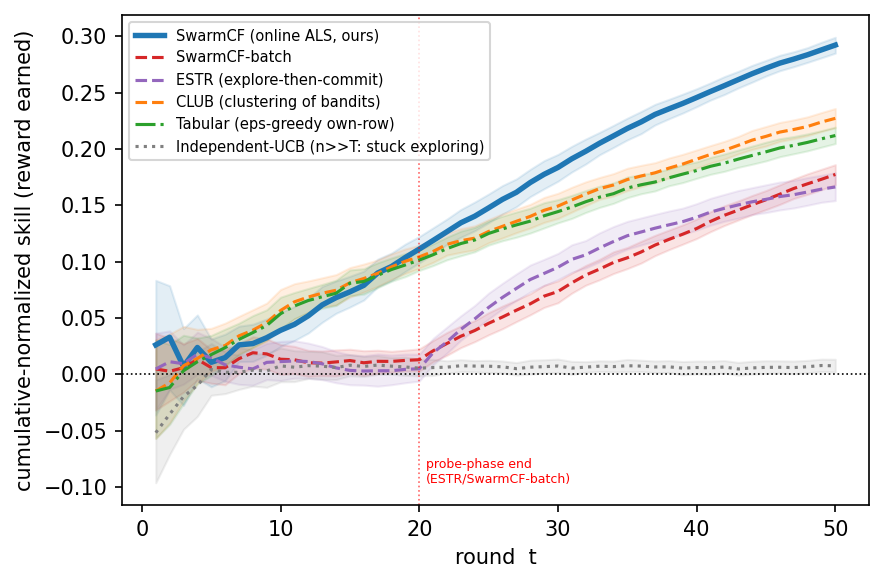
Final-policy quality can overstate a method that explores cheaply. The operationally relevant measure is reward earned while learning. Figure 3 shows cumulative-reward skill over the mission: SwarmCF earns from the first rounds. Independent-UCB stays near the random floor: with $n\gg T$ arms its optimism keeps it exploring untried tasks. Phase-structured low-rank methods pay an explore-then-commit penalty early. An $\varepsilon$-greedy tabular learner does earn some reward by re-exploiting tasks it has already engaged (each task recurs in offers about $cT/n\approx 4$ times here), but it stays well below SwarmCF and at the floor on unseen pairs (Table 3). The clean anytime collapse of Theorem 1 holds in the strict regime $cT=o(n)$ (demonstrated in Appendix E, Figure 9a); SwarmCF's early-earning advantage is broader, as seen here.
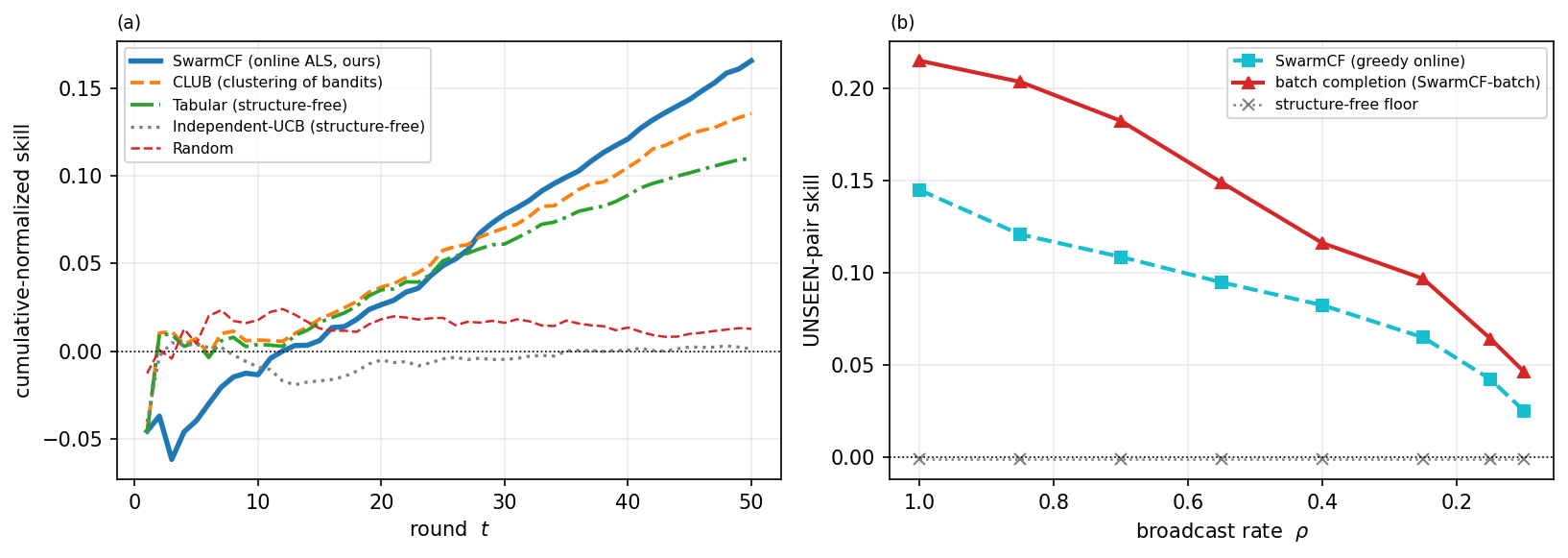
6.3 Why a swarm: the value of the broadcast and a positive scaling law
Two experiments isolate what the team and the broadcast contribute (Figure 4). (a) Value of the broadcast. Sweeping from $\rho=0$ (each robot isolated, sees only its own outcomes) to $\rho=1$ (full passive sensing): a lone robot cannot recover the shared structure from its single matrix row, so isolated unseen skill is $\approx 0$; the broadcast lifts SwarmCF by $+0.43$ unseen skill but a structure-free learner by $\approx 0$, which has no model linking tasks and so cannot use it (Theorem 3). (b) Positive scaling. Holding $n$, horizon and $\rho$ fixed and growing the team from $m=5$ to $80$, SwarmCF's unseen skill rises monotonically ($0.10\to 0.42$): more robots feed more observations into the one shared structure, so each robot's competence on tasks it never engaged grows with the team. The batch variant and the discrete-clustering baseline also rise with team size (Figure 4b), so the positive scaling is a structural property of the shared low-rank reward rather than specific to the online update, though SwarmCF stays above both at every team size. Structure-free learning is flat. A swarm whose per-robot competence rises with team size, the opposite of the usual interference penalty, is a direct consequence of sharing structure.
6.4 The cost of communication-free operation: a centralized ceiling
Table 2 consolidates the masked-harness comparison across all methods, including two structured controls that bound the explanation of the advantage. A published clustering-of-bandits baseline (CLUB [49], which shares structure through discrete robot clusters rather than continuous factors) still generalizes above the structure-free floor (unseen-pair skill $0.08$ at $\rho=0.25$), confirming the categorical gap is structure-sharing versus none rather than an artifact of our particular estimator; but with continuous latent traits and no discrete types, hard clustering loses its natural target, so SwarmCF's continuous low-rank leads it by a wide margin ($0.23$ versus $0.08$, a gap that widens relative to a type-clustered world). An additive popularity model (BiasModel [41], rank $\le 2$) captures only globally-good tasks and stays near the floor ($0.01$), so the advantage is personalized low-rank transfer, not a shared popularity ranking. Here we ask how far communication-free SwarmCF is from a centralized optimum that our constraints forbid. We add a reference ceiling (an upper bound, not a competitor): a centralized full-communication matcher that sees every reward and computes the optimal one-to-one robot-task assignment by Hungarian matching [54]. At the unrestricted all-tasks menu under capacity-1 contention (the worst case for collisions; matching-normalized so the centralized matcher is $1$ and the random-collision floor is $0$, $\rho=0.25$, $n=240$), communication-free SwarmCF recovers $0.30$ of this ceiling while the structure-free learner recovers essentially none ($0.003$). Two forces separate SwarmCF from the matcher: imperfect estimation under the masked, private broadcast, and within-round coordination, since a shared all-tasks menu drives uncoordinated greedy selections onto the same high-value tasks where only one robot wins each (capacity-1). Section 6.5 isolates the coordination component by varying contention, and Appendix E decomposes the gap with a minimal-communication reference point, finding estimation the larger force (coordination accounts for only about $0.085$ of the shortfall); a communication-free de-confliction scheme is a follow-up.
Table 2. Performance scorecard on one canonical masked harness.
One canonical masked harness (m=30, n=240, 16 seeds); unseen-skill columns report the mean with a bootstrap 95% confidence interval in brackets, regret and time-to-competence are means from the anytime trajectories; the best entry in each column is shown in bold, and never in the last column marks a method that reaches 25% of the centralized oracle in fewer than half the seeds. With continuous (no-type) latent traits, SwarmCF leads every column: lowest regret, the fastest and only reliable time-to-competence, and the highest unseen-pair skill at both the masked (ρ=0.25) and full (ρ=1) broadcast, beating the batch variant SwarmCF-batch by a margin whose 16-seed intervals do not overlap. The discrete-clustering (CLUB) and additive (BiasModel) controls generalize above the structure-free floor but stay well below SwarmCF, so the advantage is continuous personalized low-rank transfer, not discrete clustering or popularity. Structure-free learners are at the floor on the unseen columns (intervals straddling zero); on the operational columns an ε-greedy tabular learner is competitive by re-exploiting already-engaged tasks, so the categorical separation is specifically an unseen-pair (generalization) phenomenon.
| Method | Provenance | unseen skill (ρ=0.25, masked) | unseen skill (ρ=1, full) | cumulative regret (ρ=0.25, lower=better) | rounds to 25% of oracle |
|---|---|---|---|---|---|
| SwarmCF | ours | 0.227 [0.214, 0.244] | 0.432 [0.420, 0.444] | 42.5 | 41 |
| SwarmCF-batch | ours | 0.123 [0.105, 0.141] | 0.219 [0.204, 0.235] | 46.7 | never |
| MF-SGD | standard, adapted | -0.007 [-0.019, 0.006] | -0.001 [-0.013, 0.010] | 48.7 | never |
| BPMF | standard, adapted | 0.073 [0.051, 0.093] | 0.068 [0.045, 0.089] | 48.7 | never |
| ESTR | standard, adapted | 0.022 [0.009, 0.037] | 0.162 [0.146, 0.179] | 46.4 | never |
| CLUB | standard, adapted | 0.079 [0.070, 0.088] | 0.227 [0.208, 0.245] | 43.8 | never |
| BiasModel | standard, adapted | 0.014 [0.001, 0.027] | 0.035 [0.012, 0.059] | 47.0 | never |
| Independent-UCB | structure-free baseline | -0.003 [-0.007, 0.001] | -0.004 [-0.008, 0.000] | 49.8 | never |
| Tabular | structure-free baseline | -0.002 [-0.006, 0.002] | 0.004 [-0.002, 0.008] | 44.1 | never |
| Random | structure-free baseline | 0.001 [-0.003, 0.006] | 0.001 [-0.004, 0.007] | 50.0 | never |
6.5 Capacity-1 contention and communication-free de-confliction
The experiments so far impose no contention: two robots may service the same target. We now turn on capacity-1 contention in LatentSwarm, where only the first robot to select a task each round succeeds and colliding robots waste the engagement, the within-round coordination cost Section 6.4 identified as the binding constraint. Nothing else changes: the same signed low-rank reward, the same persistent private mask, the same task scarcity and randomly guessed rank, with SwarmCF run as one policy under no contention handling.
(a) The categorical separation survives contention. The generalization gap persists under capacity-1 contention: SwarmCF has the highest unseen-pair skill ($0.26$, bootstrap 95% CI $[0.23,0.30]$ over 16 seeds), well above the discrete-clustering baseline CLUB ($0.12$) and far above the structure-free learners, whose unseen-pair intervals straddle zero. On earned (anytime) skill, a clustering baseline can earn competitively by committing quickly to popular tasks: CLUB earns the most ($0.35$ of the centralized capacity-1 ceiling) with SwarmCF close behind ($0.30$), both far above MF-SGD ($0.19$) and the structure-free independent-UCB, which under the shared all-tasks menu collides on 97% of its engagements and earns essentially nothing ($0.00$, at the random floor). So contention lets a clustering baseline earn competitively, but SwarmCF keeps the decisive lead on the harder unseen-pair generalization that defines the regime, and the separation holds throughout (Figure 5). This contention study uses $\rho=0.5$, the all-tasks menu, and the capacity-1 (Hungarian) normalization, so its skill values are not directly comparable to the masked-harness numbers of Table 2 (which use $\rho=0.25$ and a size-$c$ menu); the categorical pattern and SwarmCF's unseen-pair lead are what carry across settings.
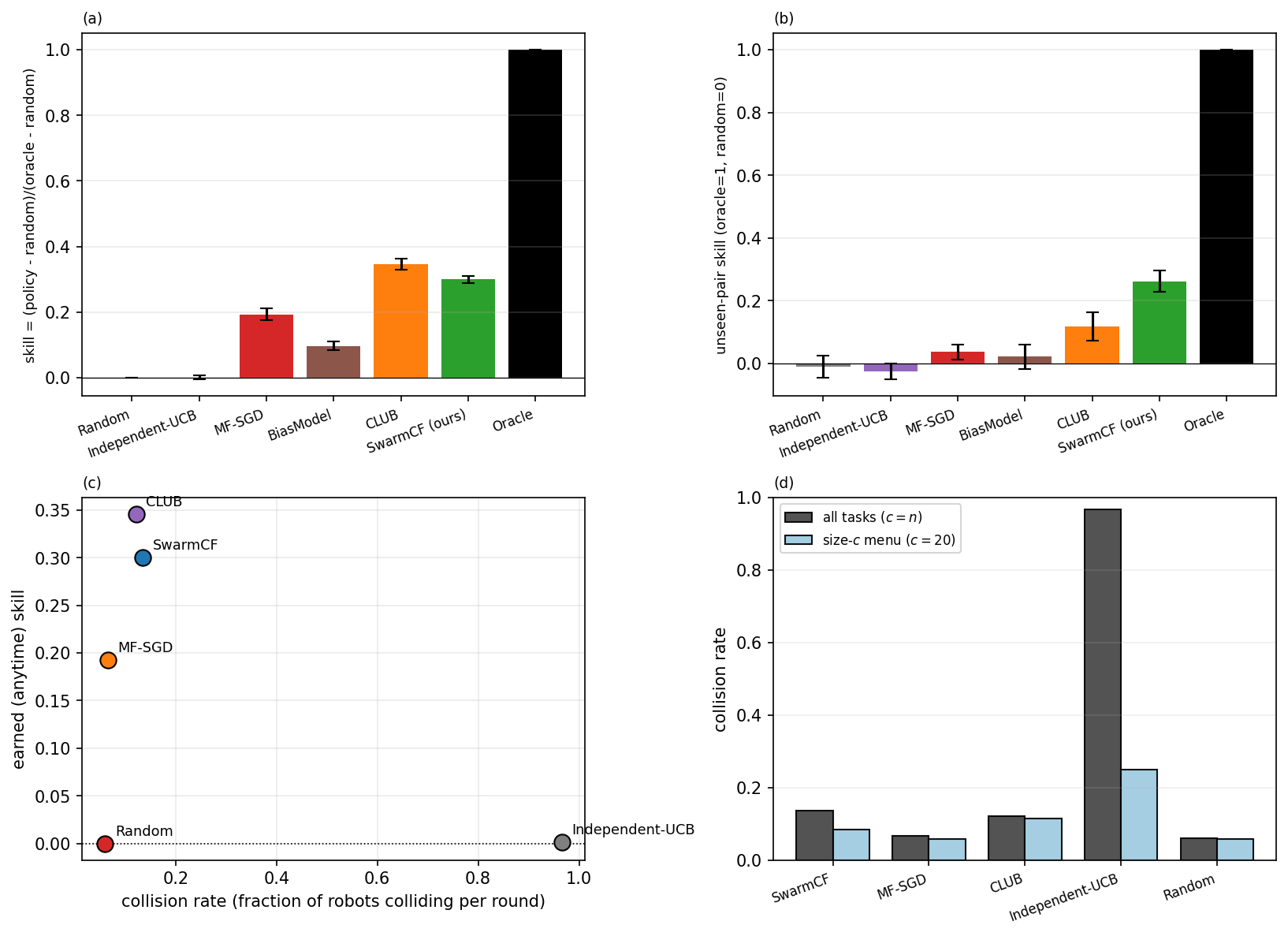
(b) The coordination gap, and how SwarmCF already mitigates it. Because the all-tasks menu offers every robot the same full set, greedy policies tend to converge on the same few high-value tasks and collide. The effect is stark (Figure 5c): the structure-free independent-UCB learner collides on almost every engagement (collision rate $\approx 0.97$) and earns essentially nothing, whereas SwarmCF collides far less (rate $\approx 0.14$) because its heterogeneous learned models send different robots to different tasks, an implicit de-confliction that emerges from the personalized low-rank estimate with no message passing. Restricting the offer to a size-$c$ menu reduces collisions for every method (independent-UCB from $0.97$ to $0.25$), one reason the body uses a size-$c$ menu. How much of the residual gap to the centralized ceiling is coordination versus estimation, measured with a minimal communication budget purely as a reference point, is quantified in Appendix E; the short answer is that for SwarmCF estimation, not coordination, is the dominant limiter.
6.6 Robustness across configurations
The separation is structural rather than tuned: it follows from the three scope conditions of Section 7 (an exploitable low-rank-but-personalized reward, task scarcity, and a shared channel), not from any particular team size or task count. Section 6.3 shows it widening with team size (Figure 4b); additional sweeps over $n$, $d$, and reward heterogeneity in the released data show the same pattern; and it stays intact when the reward is only approximately low-rank, under the offer size (size-$c$ versus all $n$ tasks), under the masking model (persistent versus i.i.d.), and under a randomly guessed rank swept from $d/2$ to $3d$, all detailed in Appendix E.
6.7 A robotics-grounded instance
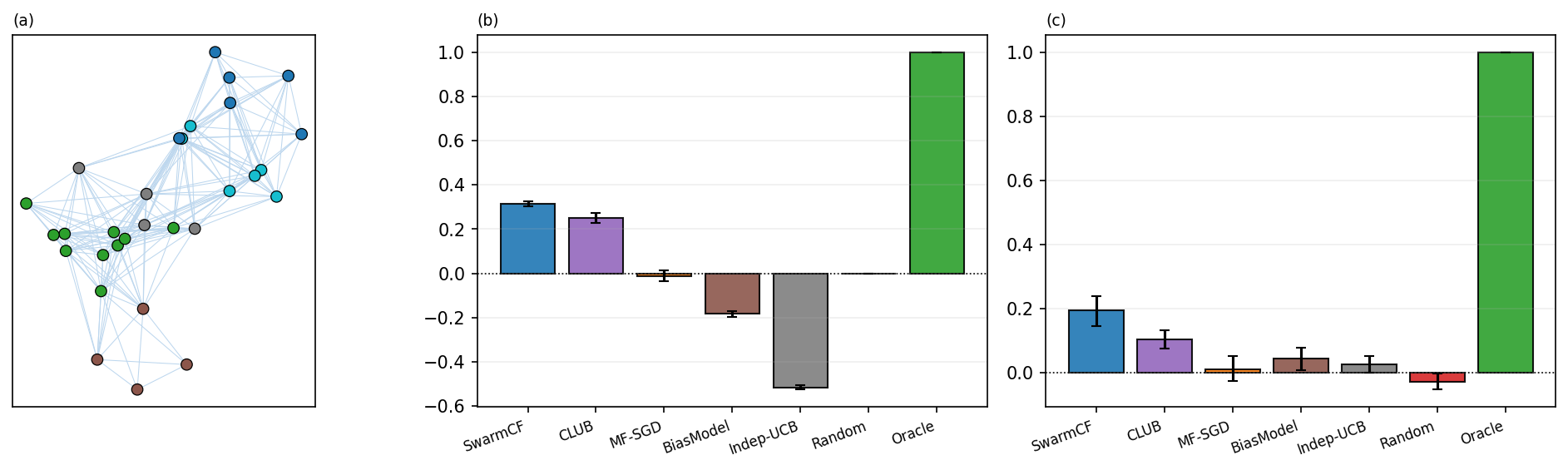
To check the separation is not an artifact of the abstract traits and Bernoulli mask, we instantiate the Section 3 model physically: robot and task vectors are non-negative profiles over $d$ sensing modalities (electro-optical, infrared, acoustic, LiDAR, range-endurance), so $R_{ij}=\langle p_i,u_j\rangle$ is a modality match (rank-$d$ by construction, in the style of trait-based MRTA [1,19,20]), and the mask is a range-limited line-of-sight graph from 2-D patrol positions with distance-growing per-observer noise (coverage-control style [10]). Under capacity-1 contention and a randomly guessed rank the separation holds: SwarmCF reaches unseen-pair skill $0.19$ (95% CI $[0.15,0.24]$) and earns 32% of the centralized ceiling, the discrete-clustering CLUB second ($0.11$), while structure-free Independent-UCB and MF-SGD sit at the floor (Figure 6). The absolute skill is lower than in the body because line-of-sight visibility is a harsher channel, so these are a separate grounded instance, not a restatement of Table 2; the separation is a property of the shared low-rank structure, not of the trait or mask model. Here the reward is still rank-$d$ by construction (a modality inner product); Appendix E complements this by grounding the reward itself, assembling it from a non-factorized detection model whose low rank is emergent rather than constructed.
7. Discussion, limitations, and future work
What the results say. Under the least information (no prior, no communication, partial and privately-noisy observation), a single simple estimator gives a swarm a capability that structure-free learning provably cannot have: acting well on the unseen, getting more competent as the team grows, and, on earned (anytime) skill, closing part of the gap to a centralized, communicating system that sees everything and coordinates perfectly, with the residual dominated by estimation, not coordination (Section 6.4, Appendix E). The separation is structural (it is a property of exploiting the shared low-rank trait structure) and operational (it shows up in reward earned while learning, and in the operational anytime and contention metrics).
Limitations. The reward is assumed (approximately) low-rank and stationary, the standard trait-based premise; the categorical advantage degrades gracefully as the structure becomes only approximately low-rank or the rank grows toward full, vanishing only when there is no exploitable structure (Appendix E, Figure 10). All our evidence is in simulation: as no existing benchmark captures this regime (Section 6) we evaluate on our own released LatentSwarm simulator. The low-rank premise, though standard for trait-based MRTA, is an assumption for any specific deployment; Appendix E shows it emerges from a physically grounded multi-sensor detection model (low rank measured, not merely posited) on which communication-free low-rank collaborative filtering remains the strongest unseen-pair predictor, but validating the premise on a physical platform remains an open problem. Rewards are real-valued and bilinear in latent traits; and the recovery rate of Theorem 2 is established for non-adaptive exploration; the finite-time rate under the strongly exploiting $\varepsilon$-decay policy our experiments actually use (which can starve low-reward tasks of spanning coverage) is bounded, loosely, by the $\varepsilon$-floor corollary of Appendix A, with the recovery-versus-horizon experiment (Appendix E) showing the practical rate.
Scope of the advantage. It is not universal, and holds when three conditions co-occur: (i) low-rank but personalized structure ($1\lt d\ll\min(m,n)$): at $d=1$ the reward reduces to a shared popularity order a bias/pooling baseline already captures; (ii) task scarcity ($n\gg T$): if instead sample-rich, a tabular learner eventually measures every entry and the unseen advantage vanishes; (iii) a shared channel ($\rho>0$): with no broadcast each robot has only its own row and collaborative filtering degenerates to tabular. Outside these conditions, structure-free methods are competitive.
Future work (a planned follow-up). The present paper deliberately keeps to a single core estimator. In a follow-up we plan to study the refinements that this foundation enables, each of which we have prototyped: (i) confidence-directed exploration via a Bayesian posterior over the factors (collective, information-directed probing through the shared broadcast); (ii) communication-free de-confliction under capacity-1 contention via a fixed private offset, against no-communication auction and musical-chairs primitives; (iii) rank self-determination (removing the guessed $\hat d$); (iv) the action/choice channel as a noise-immune alternative to cardinal rewards; and (v) non-stationarity and team churn. We also plan a tightening of the adaptive-policy coverage rate.
8. Conclusion
We formalized multi-robot task allocation in its most restrictive but practically common form (no prior knowledge, no communication, partial and privately-noisy observation), and showed that decentralized online collaborative filtering over the passive broadcast lets each robot act well on tasks it has never attempted. The advantage over structure-free learning is categorical (such a learner is provably pinned at the prior-mean floor on the unseen); the broadcast is what makes it possible and the team is what makes it fast, all without communication and while assuming far less than the centralized systems it is measured against. We hope the setting, a swarm that must learn to coordinate from only what it passively senses, becomes a useful baseline regime for autonomous multi-robot systems.
CRediT authorship contribution statement
Alexander Apartsin: Conceptualization, Methodology, Formal analysis, Visualization, Writing - original draft. Yigal Meshulam: Software, Validation, Investigation. Yehudit Aperstein: Conceptualization, Supervision, Writing - review & editing.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Data availability
The source code, the per-seed data required to reproduce every figure and table, and the LatentSwarm simulator (the masked-broadcast setting and its capacity-1 contention extension) are openly available at github.com/ApartsinProjects/ZKDroneSwarm.
References
- A. Prorok, M. A. Hsieh, V. Kumar. The impact of diversity on optimal control policies for heterogeneous robot swarms. IEEE Trans. Robotics, 33(2):346–358, 2017.
- B. Fu, W. Smith, D. Rizzo, M. Castanier, M. Ghaffari, K. Barton. Learning task requirements and agent capabilities for multi-agent task allocation. arXiv:2211.03286, 2022.
- A. Dupuy, A. Galichon. Personality traits and the marriage market. Journal of Political Economy, 122(6):1271–1319, 2014.
- F. Schilling, F. Schiano, D. Floreano. Vision-based drone flocking in outdoor environments. IEEE Robotics and Automation Letters, 6(2):2954–2961, 2021.
- X. Zhou, X. Wen, Z. Wang, Y. Gao, et al. Swarm of micro flying robots in the wild. Science Robotics, 7(66):eabm5954, 2022.
- N. Hudson, F. Talbot, M. Cox, et al. Heterogeneous ground and air platforms, homogeneous sensing: Team CSIRO Data61's approach to the DARPA Subterranean Challenge. Field Robotics, 2:595–636, 2022.
- M. Tranzatto, M. Dharmadhikari, L. Bernreiter, et al. Team CERBERUS wins the DARPA Subterranean Challenge: technical overview and lessons learned. arXiv:2207.04914, 2022.
- M. Brambilla, E. Ferrante, M. Birattari, M. Dorigo. Swarm robotics: a review from the swarm engineering perspective. Swarm Intelligence, 7:1–41, 2013.
- E. Şahin. Swarm robotics: from sources of inspiration to domains of application. LNCS 3342, Springer, 2005.
- J. Cortés, S. Martínez, T. Karatas, F. Bullo. Coverage control for mobile sensing networks. IEEE Trans. Robotics and Automation, 20(2):243–255, 2004.
- B. P. Gerkey, M. J. Matarić. A formal analysis and taxonomy of task allocation in multi-robot systems. Int. J. Robotics Research, 23(9):939–954, 2004.
- G. A. Korsah, A. Stentz, M. B. Dias. A comprehensive taxonomy for multi-robot task allocation. Int. J. Robotics Research, 32(12):1495–1512, 2013.
- E. Nunes, M. Manner, H. Mitiche, M. Gini. A taxonomy for task allocation problems with temporal and ordering constraints. Robotics and Autonomous Systems, 90:55–70, 2017.
- M. B. Dias, R. Zlot, N. Kalra, A. Stentz. Market-based multirobot coordination: a survey and analysis. Proc. IEEE, 94(7):1257–1270, 2006.
- H.-L. Choi, L. Brunet, J. P. How. Consensus-based decentralized auctions for robust task allocation. IEEE Trans. Robotics, 25(4):912–926, 2009.
- A. Khamis, A. Hussein, A. Elmogy. Multi-robot task allocation: a review of the state-of-the-art. In Cooperative Robots and Sensor Networks, Springer, 2015.
- M. Otte, M. J. Kuhlman, D. Sofge. Auctions for multi-robot task allocation in communication limited environments. Autonomous Robots, 44:547–584, 2020.
- J. Gielis, A. Shankar, A. Prorok. A critical review of communications in multi-robot systems. Current Robotics Reports, 3:213–225, 2022.
- G. Notomista, S. Mayya, S. Hutchinson, M. Egerstedt. An optimal task allocation strategy for heterogeneous multi-robot systems. European Control Conference, 2019.
- H. Ravichandar, K. Shaw, S. Chernova. STRATA: a unified framework for task assignments in large teams of heterogeneous agents. Autonomous Agents and Multi-Agent Systems, 34:38, 2020.
- Athira K. A., J. Divya Udayan, U. Subramaniam. A systematic literature review on multi-robot task allocation. ACM Computing Surveys, 2024.
- J. Rosenski, O. Shamir, L. Szlak. Multi-player bandits: a musical chairs approach. ICML, 2016.
- E. Boursier, V. Perchet. SIC-MMAB: synchronisation involves communication in multiplayer multi-armed bandits. NeurIPS, 2019.
- I. Bistritz, A. Leshem. Distributed multi-player bandits: a game of thrones approach. NeurIPS, 2018.
- C. Yu, A. Velu, E. Vinitsky, et al. The surprising effectiveness of PPO in cooperative multi-agent games. NeurIPS, 2022.
- T. Rashid, M. Samvelyan, et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. ICML, 2018.
- P. Sunehag, G. Lever, et al. Value-decomposition networks for cooperative multi-agent learning. AAMAS, 2018.
- R. Lowe, Y. Wu, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. NeurIPS, 2017.
- S. Sukhbaatar, A. Szlam, R. Fergus. Learning multiagent communication with backpropagation. NeurIPS, 2016.
- A. Das, T. Gervet, et al. TarMAC: targeted multi-agent communication. ICML, 2019.
- J. Foerster, Y. Assael, N. de Freitas, S. Whiteson. Learning to communicate with deep multi-agent reinforcement learning. NeurIPS, 2016.
- P. Goarin, G. Loianno. Graph neural network for decentralized multi-robot goal assignment. IEEE Robotics and Automation Letters, 2024.
- Z. Wang, M. Gombolay. Learning scheduling policies for multi-robot coordination with graph attention networks. IEEE Robotics and Automation Letters, 5(3):4509–4516, 2020.
- M. Ammad-ud-din, E. Ivannikova, S. A. Khan, W. Oyomno, Q. Fu, K. E. Tan, A. Flanagan. Federated collaborative filtering for privacy-preserving personalized recommendation system. arXiv:1901.09888, 2019.
- B. McMahan, E. Moore, D. Ramage, S. Hampson, B. Agüera y Arcas. Communication-efficient learning of deep networks from decentralized data. AISTATS, 1273–1282, 2017.
- D. S. Bernstein, R. Givan, N. Immerman, S. Zilberstein. The complexity of decentralized control of Markov decision processes. Mathematics of Operations Research, 27(4):819–840, 2002.
- E. J. Candès, B. Recht. Exact matrix completion via convex optimization. Found. Comput. Math., 9(6):717–772, 2009.
- R. H. Keshavan, A. Montanari, S. Oh. Matrix completion from a few entries. IEEE Trans. Inf. Theory, 56(6):2980–2998, 2010.
- B. Recht. A simpler approach to matrix completion. JMLR, 12:3413–3430, 2011.
- P. Jain, P. Netrapalli, S. Sanghavi. Low-rank matrix completion using alternating minimization. STOC, 2013.
- Y. Koren, R. Bell, C. Volinsky. Matrix factorization techniques for recommender systems. IEEE Computer, 42(8):30–37, 2009.
- R. Salakhutdinov, A. Mnih. Bayesian probabilistic matrix factorization using MCMC. ICML, 2008.
- R. Mazumder, T. Hastie, R. Tibshirani. Spectral regularization algorithms for learning large incomplete matrices. JMLR, 11:2287–2322, 2010.
- Y. Hu, Y. Koren, C. Volinsky. Collaborative filtering for implicit feedback datasets. ICDM, 2008.
- S. Rendle, C. Freudenthaler, Z. Gantner, L. Schmidt-Thieme. BPR: Bayesian personalized ranking from implicit feedback. UAI, 2009.
- Y. Kang, C.-J. Hsieh, T. C. M. Lee. Efficient frameworks for generalized low-rank matrix bandit problems. NeurIPS, 2022.
- K.-S. Jun, R. Willett, S. Wright, R. Nowak. Bilinear bandits with low-rank structure. ICML, 2019.
- Y. Lu, A. Meisami, A. Tewari. Low-rank generalized linear bandit problems. AISTATS, 2021.
- C. Gentile, S. Li, G. Zappella. Online clustering of bandits. ICML, 2014.
- Q. Ling, Y. Xu, W. Yin, Z. Wen. Decentralized low-rank matrix completion. IEEE ICASSP, 2925–2928, 2012.
- A. H. Murphy. Skill scores based on the mean square error and their relationships to the correlation coefficient. Monthly Weather Review, 116:2417–2424, 1988.
- B. Sarwar, G. Karypis, J. Konstan, J. Riedl. Incremental singular value decomposition algorithms for highly scalable recommender systems. Proc. 5th Int. Conf. Computer and Information Technology, 2002.
- P. Auer, N. Cesa-Bianchi, P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47(2–3):235–256, 2002.
- H. W. Kuhn. The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1–2):83–97, 1955.
Appendix A. Proofs and empirical validation of the main results
We give proofs of the main results below (full for Proposition 1, Lemma 1, Theorem 1, and Theorem 2; Theorem 3 follows as a corollary of Theorem 2), each closed by a short remark on the proof technique and its relation to existing results. Throughout, factors are assumed in general position (generic $P,U$), the persistent mask is $M_{ik}\sim\mathrm{Bernoulli}(\rho)$ over robot pairs, and $\hat d\ge d$.
Proposition 1 (floor). For an unobserved $j$ the estimate is a pre-chosen constant $b$; $\mathbb{E}[(b-R_{ij})^2]=(b-\mu_i)^2+\mathrm{Var}_j\ge\mathrm{Var}_j=\Omega(1)$, and on an offer of never-engaged tasks selection is independent of their rewards, giving skill $0$. The broadcast cannot help a per-task estimate by definition. Remark: elementary; it fixes the floor against which the categorical claim is measured.
Lemma 1 (row completion). Stacking the observed entries gives $R_{i,\Omega}=U_\Omega p_i$; spanning makes $U_\Omega$ full column rank, so $p_i=(U_\Omega^\top U_\Omega)^{-1}U_\Omega^\top R_{i,\Omega}$ is unique and exact, hence all $R_{ij}$. Remark: the linear algebra is standard given $U$; the contribution is the $\Theta(d)$-versus-$\Theta(n)$ contrast against the floor of Proposition 1.
Theorem 1 (anytime). (a) A structure-free learner's estimate on any never-engaged task equals the prior, so on an offer it can only rank tasks it has already engaged and is reward-blind on every other offered task. Its per-round skill is thus $\le 1$ when the offer contains an already-engaged task and has expectation $0$ otherwise, so $\mathbb{E}[\mathrm{skill}_t]\le\Pr[\text{offer contains an engaged task}]$. After $t-1$ rounds at most $t-1$ distinct tasks are engaged, and each lies in the uniform size-$c$ offer with probability $c/n$, so a union bound gives this probability $\le c(t-1)/n$. Averaging over the mission (with i.i.d. offers the oracle-minus-random normaliser is identically distributed across rounds) yields expected cumulative-reward skill $\le\tfrac1T\sum_{t=1}^{T}c(t-1)/n=c(T-1)/(2n)$. (b) After recovery (Theorem 2) the completed row is exact in the noiseless case, so greedy selection earns per-round skill $1$ thereafter; for $T=\omega(T_{\mathrm{rec}})$ the pre-recovery rounds are a vanishing fraction, giving anytime skill $\Omega(1)$ (under noise, $1-O(\sigma\sqrt{d/|E_i(j)|})$ per round). Remark: the constant is explicit ($1/2$); a tighter distribution-dependent rate replaces $c(t-1)/n$ by the expected normalised best-of-subset order statistic. We also confirm the bound empirically.
Theorem 2 (recovery). A fully-observed invertible $\hat d\times\hat d$ block pins the factor frame; per task, $R_{E_i(j),j}=B\,u_j$ with $B=P_{E_i(j)}$ determines $u_j$ uniquely iff $B$ has full column rank, and determines the pair $\langle p_i,u_j\rangle$ iff $p_i\in\mathrm{span}\{p_k:k\in E_i(j)\}$ (the per-task analogue of Proposition 1). With noise the error is $O(\sigma\sqrt{d}/\sigma_{\min}(B))=O(\sigma\sqrt{d/|E_i(j)|})$ since generically $\sigma_{\min}(B)=\Theta(\sqrt{|E_i(j)|})$. Coverage time (non-adaptive policy): each visible teammate engages each task with probability $\approx 1/n$ per round (for any menu size $c$: task $j$ is offered with probability $c/n$ and then selected with probability $\approx 1/c$), so it has engaged task $j$ at least once after $T$ rounds with probability $1-(1-1/n)^T\approx 1-e^{-T/n}$; the number of distinct visible engagers of $j$ is $\mathrm{Binomial}(|N_i|,1-e^{-T/n})$ with $|N_i|\approx\rho m$, and requiring $\ge d$ spanning engagers for all $n$ tasks with a union bound gives $T=O\!\big(\tfrac{nd}{\rho m}\log n\big)$, which decreases in the team size $\rho m$ and requires $\rho m>d$. Remark: the condition is deterministic and is validated empirically at the end of this appendix. We are not aware of a comparable recovery condition for a persistent, per-observer mask, the regime where uniform-sampling matrix-completion guarantees do not apply; the finite-time rate under the strongly-exploiting (adaptive) policy we run is bounded by the corollary below.
Corollary (recovery under the $\varepsilon$-greedy policy). The rate above assumes non-adaptive (uniform) exploration. Under the $\varepsilon$-greedy policy we actually run, with a constant exploration floor $\varepsilon_{\min}>0$ (each robot selects a uniformly random offered task with probability at least $\varepsilon_{\min}$ every round), the spanning condition of Theorem 2 still holds for all tasks with high probability after $T=O\!\big(\tfrac{nd}{\rho m\,\varepsilon_{\min}}\log n\big)$ rounds. Proof. Restrict to exploration engagements: a visible teammate explores with probability $\ge\varepsilon_{\min}$ and then engages a given task with probability $\approx 1/n$, so it covers each task at rate $\ge\varepsilon_{\min}/n$; applying the coverage and union-bound argument of Theorem 2 to this $\varepsilon_{\min}$-thinned sub-process gives the stated time, and exploitation engagements only add coverage. $\square$ Remark: the bound is the non-adaptive rate inflated by $1/\varepsilon_{\min}$ (here $20\times$ at $\varepsilon_{\min}=0.05$); it is loose because exploitation also covers the high-value tasks and, more to the point, acting well needs only correct ranking of each offered set (graded recovery of the high-value tasks), not full recovery of every task. The recovery-versus-horizon experiment (Appendix E, Figure 13) makes this concrete: under uniform exploration the recovery fraction reaches $\approx 0.99$ near $T_{\mathrm{rec}}$ (the Theorem 2 regime), whereas the $\varepsilon$-greedy policy recovers more slowly (about $0.52$ by $T_{\mathrm{rec}}$, as the $1/\varepsilon_{\min}$ factor predicts); yet SwarmCF already attains its operational skill at the body's $T=50$, where only about $14\%$ of pairs are formally recovered, because ranking needs graded recovery of the high-value tasks, not full recovery of every task.
Theorem 3 (collective speedup). (a) At $\rho=0$ robot $i$ sees only its own engaged entries $\langle p_i,u_j\rangle$ with $U$ unknown; for $d>1$ these place no constraint on $\langle p_i,u_{j'}\rangle$ at an unseen $j'$, so the estimate is the prior (Proposition 1) and unseen skill is $0$. (b) For $\rho>0$ this is Theorem 2 specialised: its per-task coverage argument gives all-task recovery after $T_{\mathrm{rec}}=O((nd/\rho m)\log n)$ rounds, decreasing as $1/m$; the only suppressed factor is the $\log n$ union bound over tasks. Remark: a corollary of Theorem 2; it is the formal counterpart of the value-of-broadcast and positive-scaling results in Section 6.3. The fold-in perturbation bound used above (cold-start error $=$ basis-recovery $+$ own-probe noise $+$ ridge bias, exact at $k\ge d$) is stated in Appendix B.
Empirical validation of the recovery condition (Theorem 2). On the swarm's actual coverage patterns ($m=30,n=240,d=5,\rho=0.5$, noiseless to isolate identifiability), reconstructing each unseen pair $(i,j)$ from the observed entries by least squares gives error at numerical zero (below $10^{-10}$) when robot $i$'s factor lies in the span of its visible engagers of $j$ (the condition of Theorem 2), versus a prior-floor reconstruction error of $\approx0.30$ (an error, not a skill) otherwise, with graceful partial recovery as the spanning rank rises to $d$. The identifiability threshold is therefore exactly the spanning condition of Theorem 2.
Appendix B. The fold-in error bound
For a newcomer factor $x_\star$ probed against an estimated basis $\hat B=B+\Delta$ ($\lVert\Delta\rVert\le\varepsilon$) with $k\ge d$ observations of noise $\sigma$ and ridge $\lambda$, the ridge fold-in prediction error splits, by a standard ridge-perturbation argument, cleanly into three sources, $\mathbb{E}|\hat r-r|\le C_1\varepsilon\lVert x_\star\rVert(1+\lVert b\rVert/s) + C_2\lVert b\rVert\sigma\sqrt{d}/s + C_3\lambda\lVert x_\star\rVert\lVert b\rVert/s^2$ with $s=\sigma_{\min}(B)$, and is exact ($\hat r=r$) when $\varepsilon=\sigma=0,\lambda\to0,k\ge d$. It quantitatively explains the graceful degradation of cold-start skill as sensing becomes sparser.
The fold-in itself (referenced from Section 4) is a single ridge solve: it recovers a newcomer's $\hat d$-vector from a few observations against the known factor basis, after which the newcomer can be scored against any other entity.
Appendix C. Reproducibility and methods compared
The headline experiments draw the latent traits i.i.d. and uniformly on the unit sphere (no discrete robot or task types), giving the signed low-rank reward of Section 3 (the grounded instance of Section 6.7 and the robustness studies of Appendix E deliberately vary the reward model, as noted there), and report bootstrap 95% confidence intervals; the broadcast-rate, anytime, bake-off (Table 2), contention (Section 6.5), and scaling sweeps all use 16 random seeds; each reported number is averaged over the per-seed runs. The code and per-seed data needed to regenerate every figure and table are openly available (see Data availability).
Hyperparameters. Headline configuration: $m=30$ robots, $n=240$ tasks, true rank $d=5$, guessed rank $\hat d$ drawn at random per run in $[d,2d]$, horizon $T=50$, offer size $c=20$ (the unrestricted all-tasks menu, $c=n$, is the offer-size variant of Appendix E), own-observation noise $\sigma_{\mathrm{own}}=0.1$, broadcast-observation noise $\sigma_{\mathrm{obs}}=0.3$, persistent mask rate $\rho$ swept. SwarmCF: $\varepsilon$-greedy with $\varepsilon_0=0.5$ decaying by $0.93$ per round to $\varepsilon_{\min}=0.05$; ridge $\lambda=10^{-2}$; 8 alternating-least-squares sweeps per refit; refit every 3 rounds; uniform observation weights (the noise level is not used). Identical exploration schedules and the same guessed rank $\hat d$ are given to every structured baseline for fairness; the choices are conservative for our claims (generous to baselines).
Table 3. Operating profiles of the methods compared (referenced from Section 6); SwarmCF-family refinements are deferred to future work (column abbreviations are defined in the key).
Column key. Observability: full = every engagement seen noiselessly; ρ = a fraction ρ of engagements seen (masked); ρσ = masked and read with per-observer noise; fullσ = unmasked but noisy; self = own outcomes only. Prior: – = none; $\hat d$ = a guessed rank; d = the true rank; U* = oracle factors. Computation: ETC = explore-then-commit. In our harness every method runs decentralized and communication-free (one estimator per robot on the passive broadcast); the low-rank methods differ only in the update rule, so the comparison is controlled. SwarmCF (our online method) and its batch variant SwarmCF-batch are ours (shaded); the rest are standard low-rank estimators we adapt, the structure-free paradigm, or reference ceilings (full communication, not competitors).
| Method | Provenance | Distribution | Communication | Observability | Prior | Computation |
|---|---|---|---|---|---|---|
| SwarmCF | ours | decentralized | none | ρσ | $\hat d$ | online |
| SwarmCF-batch | ours | decentralized | none | ρσ | $\hat d$ | batch |
| MF-SGD | standard, adapted | decentralized | none | ρσ | $\hat d$ | online |
| BiasModel | standard, adapted | decentralized | none | ρσ | – | online |
| BPMF | standard, adapted | decentralized | none | ρσ | $\hat d$ | batch |
| CLUB | standard, adapted | decentralized | none | ρσ | – | batch |
| ESTR | standard, adapted | decentralized | none | ρ | $\hat d$ | ETC |
| Independent-UCB | structure-free baseline | decentralized | none | ρσ | – | online |
| Tabular | structure-free baseline | decentralized | none | ρσ | – | online |
| Random | structure-free baseline | decentralized | none | – | – | – |
| Centralized (clean) | reference (upper bound) | centralized | full | full | $\hat d$ | online |
| Centralized (noisy) | reference (upper bound) | centralized | full | fullσ | $\hat d$ | online |
| Oracle | reference (upper bound) | centralized | full | full | U* | – |
Appendix D. The LatentSwarm environment
The LatentSwarm package (a modular, pip-installable Python package) is our simulator for ZK-MRTA (Section 6.5 adds capacity-1 contention). Its components are registered by name and selected by configuration: scenario builders (latent-trait generation), the environment, the policy library, the metrics, and the visualizations are separate pluggable modules, so a study is fully specified by one configuration object. It uses the Section 3 reward and observation model and adds capacity-1 contention, and SwarmCF enters only as one drop-in policy among the package's own (random, Hungarian oracle, MF-SGD, Independent-UCB).
Model. The environment uses the Section 3 reward and observation model verbatim: each robot $i$ and task $j$ gets a hidden $d$-vector drawn i.i.d. and L2-normalized to the unit sphere (no latent types), giving the signed low-rank reward $r_{ij}=\langle p_i,u_j\rangle$; robots do not communicate and read the public outcome stream through a persistent per-pair mask $M_{ik}\sim\mathrm{Bernoulli}(\rho)$ ($M_{ii}=1$) with independent per-observer noise $\eta_{ik}\sim\mathcal N(0,\sigma^2)$, so no two robots see the same stream. To this it adds capacity-1 contention (only the first robot to pick a task each round succeeds; a colliding robot earns nothing) over a task-scarce ($n\gg T$) horizon, with a randomly guessed rank $\hat d$ and exploration schedule shared by every structured method. Algorithm 3 gives the full mission loop.
Metrics. Earned (anytime) skill normalizes the mean per-round reward to $(\text{policy}-\text{random})/(\text{oracle}-\text{random})$, where the oracle is the per-round optimal one-to-one (Hungarian) matching of robots to distinct tasks, the centralized capacity-1 ceiling. Unseen-pair skill measures each robot's decision quality on tasks it never engaged, from its learned model, self-normalized so the oracle is $1$ and random is $0$. The configuration is $m=30$, $n=240$, $d=5$, $\hat d\sim\mathrm{Uniform}\{d,\dots,2d\}$, all $n$ tasks offered, $T=50$, $\rho=0.5$, $\sigma=0.3$, with 16 seeds and bootstrap 95% confidence intervals.
Appendix E. Robustness and trait-distribution sensitivity
Two evaluation choices in the body are robustness knobs rather than load-bearing assumptions: the offer size and the masking model. We vary each here and find the categorical separation and the masking-robustness of SwarmCF unchanged.
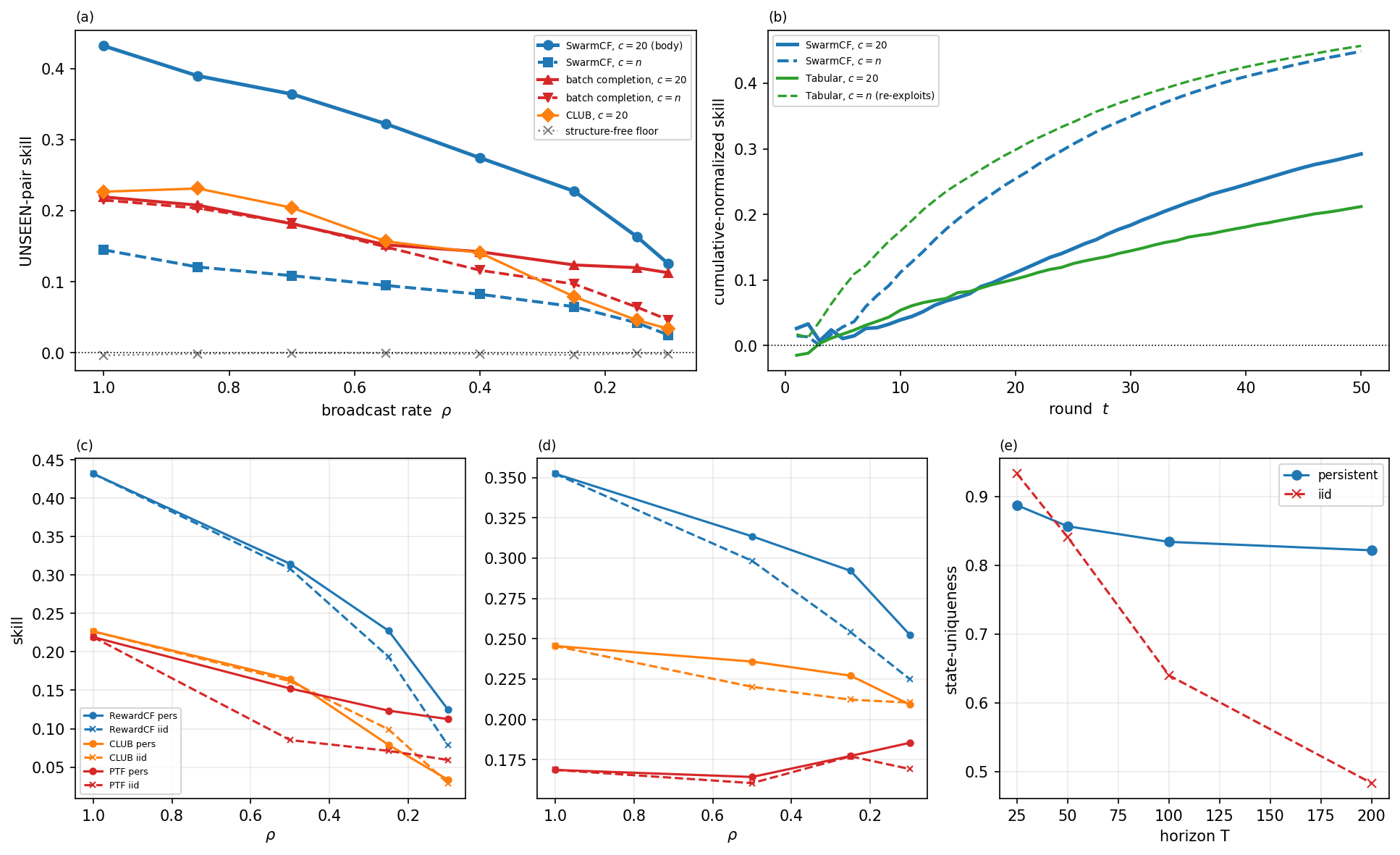
Offer size. The body restricts each offer to a uniform random size-$c$ subset ($c=20$); here we instead offer every robot all $n$ tasks each round (the unrestricted menu, $c=n$). Figure 7 (top row) repeats the masking sweep under both menus. The categorical result is unchanged: every low-rank method stays well above the structure-free floor at both menu sizes (Figure 7a), so the structure-versus-no-structure separation, the paper's main claim, does not depend on the offer size. What changes is the ordering among low-rank methods. Under the size-$c$ menu the per-round random offers force each robot to engage a varied set of tasks, giving the online estimator the coverage it needs, so SwarmCF leads the batch completers; under the all-tasks menu every robot instead selects greedily over all $n$ tasks, the collective engagement coverage narrows, and SwarmCF's unseen-pair skill falls to or below the batch and probe-based methods, whose scheduled exploration is insensitive to the menu. The advantage of an online greedy estimator over batch completion is therefore contingent on the offered menu supplying exploration diversity; a probe phase (the hybrid variant) or a non-greedy menu restores it. This is a limitation of the greedy online policy, not of the low-rank approach, whose categorical advantage over structure-free learning is unaffected. More generally, replacing the uninformed $\varepsilon$-greedy probe with confidence-directed exploration, a Bayesian posterior over the factors that probes where the shared structure is least pinned down, restores coverage without a fixed probe budget; we develop this in a follow-up.
Masking model. The body uses a persistent observation mask (each pair $(i,k)$ is visible or not for the whole mission). An i.i.d. per-round mask redraws visibility every round, which reduces to standard uniform sub-sampling of the broadcast. Figure 7 (bottom row) compares the two. Final-policy unseen skill and anytime skill are essentially invariant to the masking model, as Theorem 3 predicts; what differs is decentralization durability: under the persistent mask each robot keeps a permanently different view, so the robots' learned models stay distinct (state-uniqueness is durable), whereas under the i.i.d. mask the blind spots average out over rounds and the models converge (state-uniqueness is transient, decreasing with the horizon). The persistent mask is therefore the harder, more realistic regime, and is the one used throughout the body.
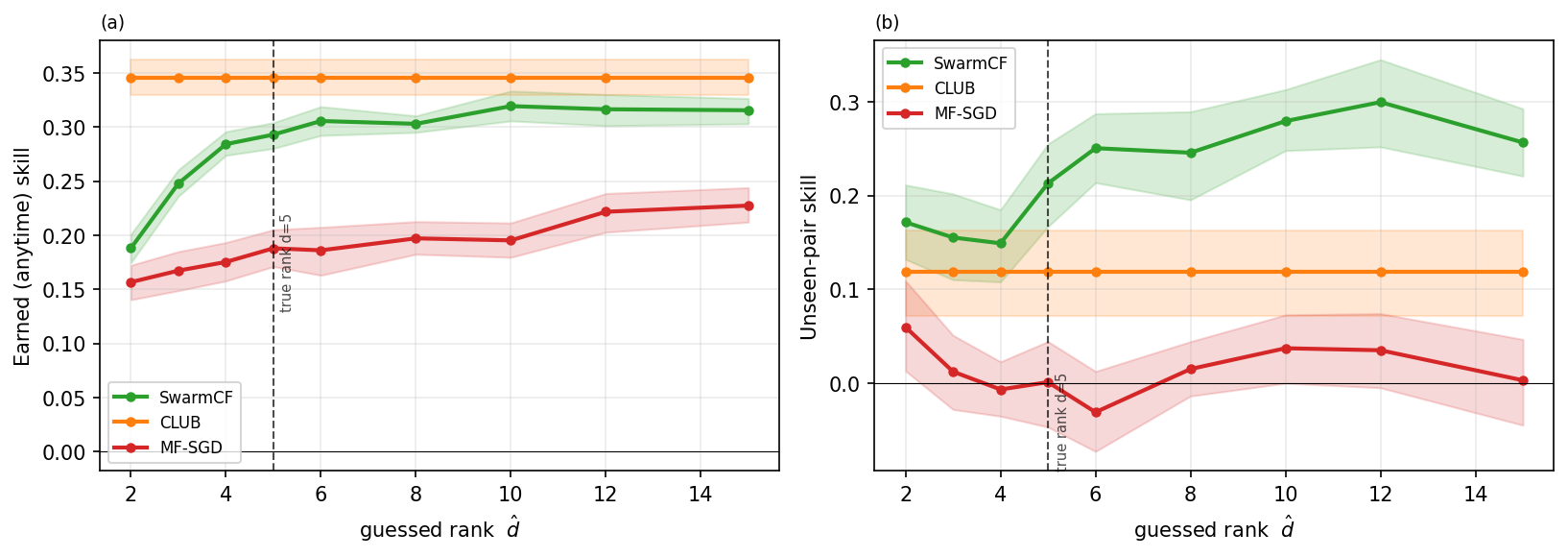
Guessed rank. Because the true rank is unknown, the guessed rank $\hat d$ is drawn at random per run; we sweep it from $d/2$ (under-ranking) to $3d$ (over-ranking) at true rank $d=5$. SwarmCF degrades only gracefully when under-specified ($\hat d\lt d$: unseen-pair skill around $0.15$ to $0.17$) and improves then stays robust once the rank is sufficient ($\hat d\ge d$: $0.21$ rising to about $0.30$ up to $\hat d=3d$), because surplus directions are shrunk by the ridge; MF-SGD stays near the floor throughout. Over-guessing is therefore safe and the exact rank is not needed (Figure 8). Removing the guess entirely, for example by letting automatic relevance determination prune the latent directions the masked design does not excite, is a natural next step we leave to a follow-up.
Theorem 1's strict regime. The body's anytime comparison (Figure 3) uses a size-$c$ menu with $cT/n\approx 4$, outside the strict scarce-offer regime $cT=o(n)$ in which Theorem 1 predicts the structure-free anytime collapse. Figure 9a re-runs the anytime comparison in that strict regime ($c=3$, $cT/n\lt 1$): the structure-free learners' cumulative skill collapses to the floor exactly as Theorem 1 states, while SwarmCF still earns, so the theorem operates as predicted when its hypothesis holds.
Restoring the online lead under the all-tasks menu. The narrowing of SwarmCF's lead over batch completion under the all-tasks menu (Figure 7) is a property of uninformed greedy exploration, not of the online estimator: adding a short UCB probe phase (a hybrid that probes, then runs online ALS) restores the lead at $c=n$ across broadcast rates (Figure 9b). The contingency is the exploration schedule, which a probe, or the confidence-directed exploration of the follow-up, repairs.
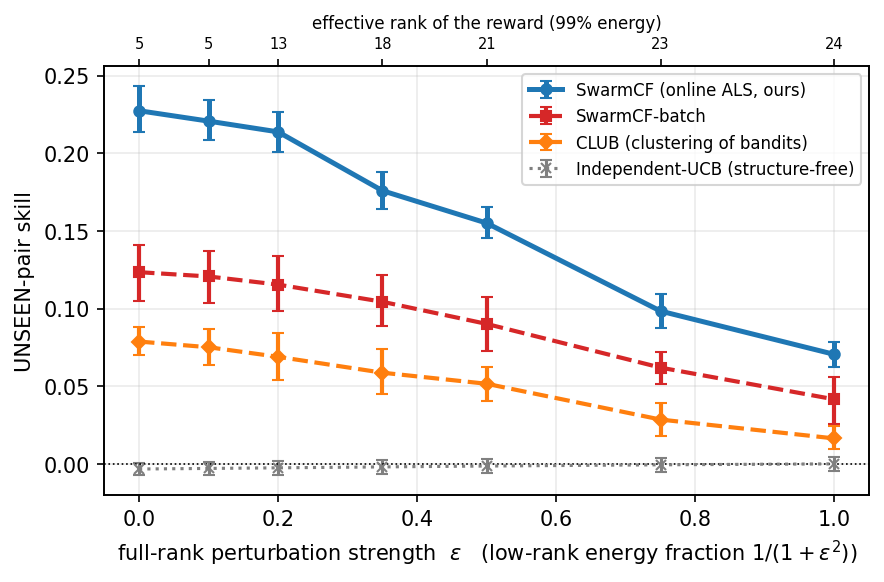
Approximate low-rank. The categorical separation assumes the reward is low-rank; we test how it degrades when the reward is only approximately so. We perturb the rank-$d$ reward with a full-rank Gaussian term, $R_\varepsilon=(R+\varepsilon\,s\,G)/\sqrt{1+\varepsilon^2}$ ($G_{ij}\sim\mathcal N(0,1)$, $s=\mathrm{std}(R)/\mathrm{std}(G)$), which holds the entry-wise scale fixed (so the observation SNR is unchanged) while moving energy out of the rank-$d$ subspace: the low-rank energy fraction is $1/(1+\varepsilon^2)$ and the effective rank rises from $d$ toward $\min(m,n)$ as $\varepsilon$ grows. Figure 10 sweeps $\varepsilon$ at the masked headline $\rho=0.25$. SwarmCF degrades gracefully: unseen-pair skill falls from 0.23 at $\varepsilon=0$ (effective rank 5) to 0.16 at $\varepsilon=0.5$ (effective rank about 21; roughly 80% of the reward energy still low-rank) and 0.07 at $\varepsilon=1$ (effective rank about 24; about 50%), staying above the structure-free floor (about 0 at every $\varepsilon$, intervals straddling zero). The advantage is therefore a property of exploitable low-rank structure, not of exact low-rankness: it weakens smoothly as structure is destroyed and reaches the floor only when essentially none remains.
The low-rank premise is emergent. The body builds the reward by construction as $R=PU^\top$, so a reader may ask whether low rank is an artifact of that choice rather than a property of physical sensing. The grounded instance of Section 6.7 still builds the reward as a rank-$d$ modality match; here we drop that and assemble a robot-by-task reward from an independent multi-sensor detection model that never factorizes it, then measure its singular spectrum. Each robot has a continuous non-negative gain profile over $S$ sensing modalities and a position; each task has a modality signature and a position. The per-modality detection probability is a rectified-linear function of the matched-filter SNR (the modality match $a_{is}b_{js}$ attenuated by a smooth range falloff), and the reward is the probability that at least one modality fires, $R_{ij}=1-\prod_s(1-p_{ijs})$: a product of misses with a nonlinear range term, not an inner product, so nothing forces it to be low-rank, yet it is low-rank in practice. The spectrum decays fast (Figure 11a): at $S=4$ about five singular values carry 95% of the energy out of $\min(m,n)=30$. The measured effective rank tracks the number of sensing modalities, rising roughly as $S{+}1$ and staying far below the ambient dimension from $S=2$ to $8$ (Figure 11b); a pure Gaussian coverage kernel behaves the same way (released data). Low rank is therefore a measured consequence of heterogeneous sensing (a few modalities and a smooth coverage geometry), not an artifact of the construction, and is the physically grounded counterpart to the approximate-low-rank robustness above.
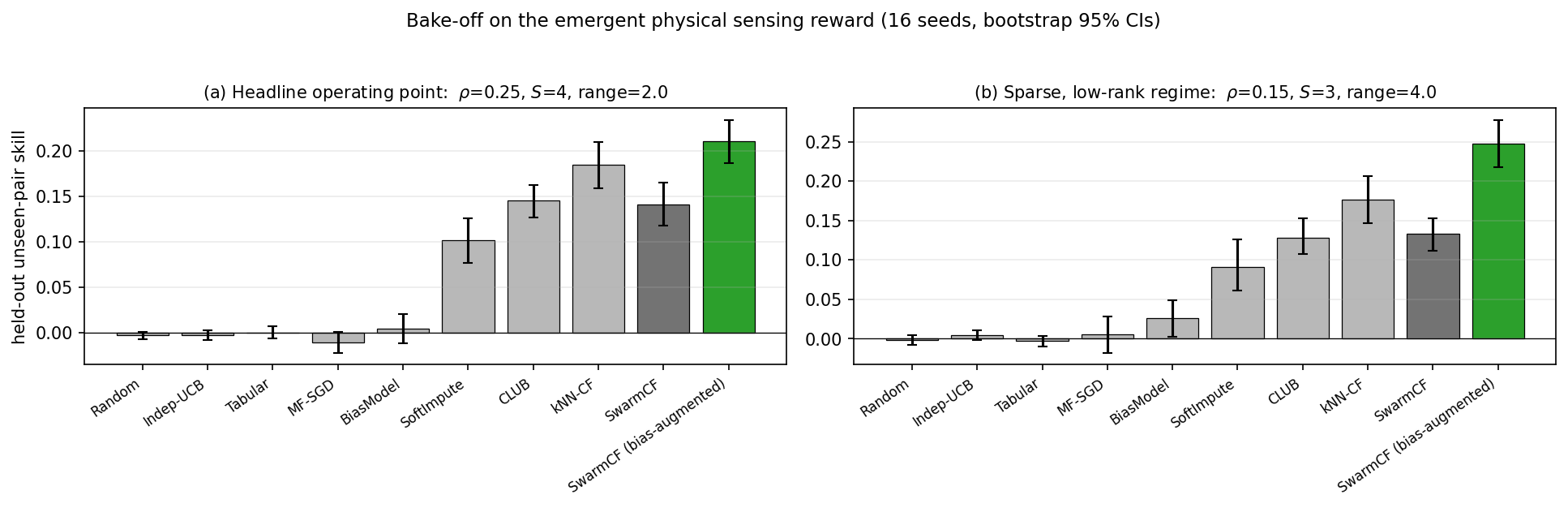
Methods on the emergent reward. We run the masked bake-off directly on this physically assembled reward (16 seeds). Unlike the body's centered $R$, the detection reward has a nonzero additive level (some tasks are intrinsically easier to detect, some robots are better detectors), so each robot uses the standard bias-augmented collaborative filter, predicting $\mu+b_i+c_j+\langle p_i,u_j\rangle$ [41]: the per-robot and per-task biases absorb that level and the rank-$\hat d$ factors model the residual interaction. This is the general form of the estimator, and it reduces to the body's SwarmCF on a centered reward (the biases vanish), so the body's results are unaffected; conversely, on the body's zero-mean rewards the explicit biases carry no signal and marginally increase variance, so the body retains the plain form and the bias terms are added only here, where the detection reward's nonzero level makes them load-bearing. Figure 12 reports held-out unseen-pair skill at two operating points: the headline channel ($\rho=0.25$, $S=4$) and a sparser, lower-rank, longer-range point ($\rho=0.15$, $S=3$) typical of a communication-starved swarm sensing by signature at range. At both, bias-augmented SwarmCF attains the highest skill in the field, above memory-based kNN-CF, convex SoftImpute, discrete-clustering CLUB, additive BiasModel, and the structure-free floor; at the sparser point the margin is pronounced ($0.247$ versus $0.177$ for the next-best baseline, with non-overlapping 95% intervals). The bias term is load-bearing here: without it the plain estimator falls below kNN-CF, because the ridge shrinks the sparsely observed task factors toward zero rather than toward the reward's level. Communication-free low-rank collaborative filtering is thus the strongest unseen-pair predictor on an emergent, physically grounded low-rank reward, not only on the constructed one.
Trait distribution. The body draws latent traits i.i.d. on the unit sphere with no discrete types (uniform_cosine). To check the categorical separation is a property of shared low-rank structure rather than of that particular distribution, we re-run the masked bake-off (the Table 2 harness, $\rho=0.25$, 16 seeds) on three trait-generating distributions, varying only the scenario: block (discrete latent types, the regime most favorable to clustering), uniform (the body's no-types headline), and approximate low-rank (continuous traits perturbed off the rank-$d$ subspace, $\varepsilon=0.5$, so about 80% of the reward energy is low-rank; the full $\varepsilon$-sweep is above). This is also where we evaluate the two further structure-sharing baselines noted in Section 6, memory-based kNN-CF and convex nuclear-norm completion SoftImpute. Table 4 reports held-out unseen-pair skill.
Table 4. Unseen-pair skill by trait distribution (masked harness, $\rho=0.25$, 16 seeds; means, with bootstrap 95% CIs in the released data). SwarmCF leads in every distribution and its 16-seed intervals exceed every baseline; the structure-free learners (Independent-UCB, MF-SGD) sit at the floor throughout (intervals straddling zero).
| Method (paradigm) | block (discrete types) | uniform (no types) | approx. low-rank (ε=0.5) |
|---|---|---|---|
| Independent-UCB (structure-free) | −0.002 | −0.003 | −0.001 |
| MF-SGD (low-rank, online SGD) | −0.008 | −0.007 | −0.011 |
| BiasModel (additive popularity) | 0.084 | 0.014 | 0.005 |
| BPMF (Bayesian low-rank) | 0.169 | 0.073 | 0.044 |
| CLUB (discrete clustering) | 0.155 | 0.079 | 0.052 |
| kNN-CF (memory-based CF) | 0.220 | 0.130 | 0.090 |
| SoftImpute (convex completion) | 0.220 | 0.163 | 0.115 |
| SwarmCF (ours, continuous low-rank) | 0.296 | 0.227 | 0.155 |
Three things hold across all three distributions. (i) The categorical separation is invariant: every structure-sharing method lifts above the structure-free floor, and the structure-free learners stay at it. (ii) SwarmCF leads on the unseen everywhere (0.296 block, 0.227 uniform, 0.155 approximate), with the convex completer SoftImpute the strongest baseline in the continuous worlds (0.163 uniform) and memory-based kNN-CF next (0.130), both well below SwarmCF. (iii) The discrete-clustering CLUB is competitive only where there are types to cluster: its unseen skill is 0.155 in the block world (about half of SwarmCF) but roughly halves to 0.079 in the no-types uniform world, while SwarmCF falls only from 0.296 to 0.227. This is the quantitative form of the Section 6.4 observation that continuous low-rank's advantage over hard clustering widens as discrete types disappear. Under approximate low-rank every method degrades gracefully and SwarmCF stays about three times CLUB, consistent with the approximate-low-rank sweep above. The separation is therefore a property of exploiting shared low-rank structure, not an artifact of the uniform trait distribution.
Coordination versus estimation (a partial-communication reference point). Section 6.4 attributes the gap to the centralized capacity-1 ceiling to two forces, imperfect estimation and within-round coordination. To quantify the split we add a minimal communication budget purely as a reference point (it is not part of the communication-free method): each robot announces its intended task each round and contention is resolved by sequential greedy assignment over still-unclaimed tasks, at a cost of $O(m)$ one-task-id messages per round. This removes SwarmCF's residual collisions (rate $0.135\to 0$) and lifts its earned skill from $0.300$ to $0.385$ of the capacity-1 ceiling, a gain of $+0.085$; the dominant remaining gap (to $1.0$) is estimation under the masked, private broadcast, not coordination. So for SwarmCF, whose heterogeneous models already de-conflict implicitly, coordination is the smaller limiter and estimation the larger, and this $+0.085$ bounds the earned-skill gain that any communication-free de-confliction can recover here. Closing this residual collision gap without communication is a follow-up direction, where candidate mechanisms (fixed private per-robot offsets, or randomized near-best action selection that breaks ties stochastically rather than greedily) can be evaluated against the collision baseline measured here.
Recovery versus horizon. The body operates at $T=50$, well below the worst-case full-recovery time $T_{\mathrm{rec}}\approx 877$ rounds (Theorem 2 at $n=240,d=5,m=30,\rho=0.25$). Sweeping the horizon (Figure 13), the Theorem 2 recovery fraction (share of pairs whose spanning condition holds) under the non-adaptive uniform-exploration policy the theorem assumes climbs to $\approx 0.99$ by $T\approx T_{\mathrm{rec}}$, confirming the theorem's regime is reached empirically. The $\varepsilon$-greedy policy we actually run recovers more slowly (to $\approx 0.52$ at $T_{\mathrm{rec}}$), consistent with the $1/\varepsilon_{\min}$ inflation of the corollary in Appendix A, because exploitation diverts coverage from low-reward tasks. Crucially, SwarmCF's operational unseen-pair skill is already attained at $T=50$, where only $\approx 14\%$ of pairs are formally recovered: acting well needs correct ranking, i.e. graded recovery of the high-value tasks, not full recovery of every pair, which is why the body's short horizon suffices.