Selecting the correct hypothesis from a candidate set, given a question and a corpus of news articles, is the core operation behind many applied forecasting tasks: geopolitical event categorization, earnings outcomes, prediction-market resolutions, medical differentials. LLMs approach this as implicit hypothesis evaluation in a single generation, weighing competing explanations without enforcing systematic evidence comparison. We argue this is the wrong granularity. Structured analytical methods from the intelligence community, in particular Analysis of Competing Hypotheses (ACH), were designed to decompose multi-hypothesis comparison into ordered, auditable steps with explicit evidence tracking.
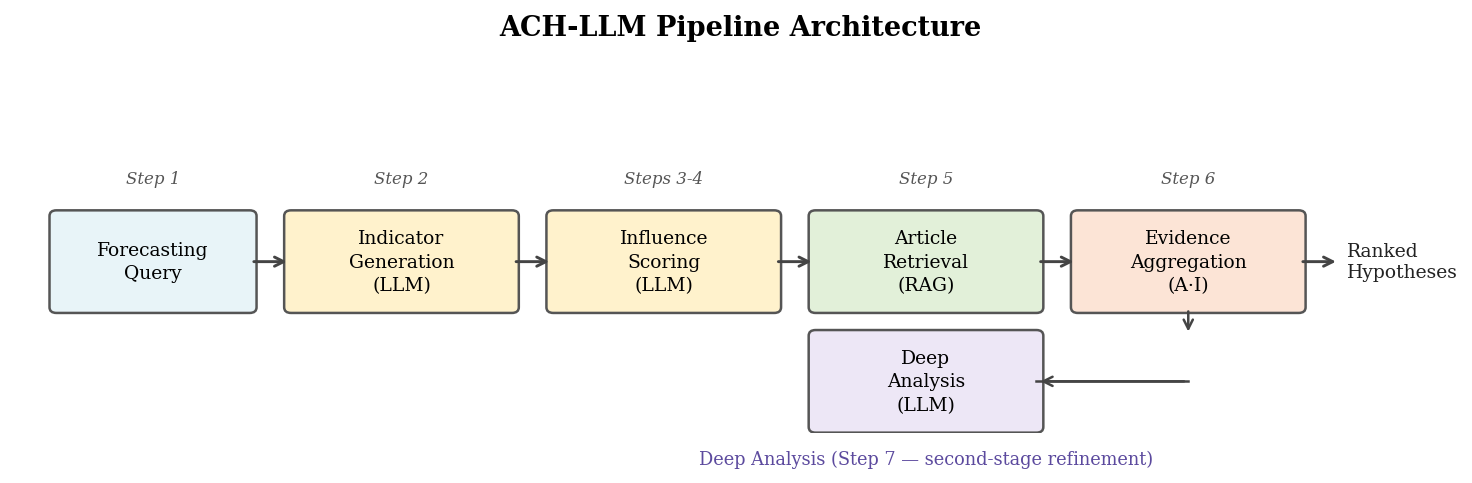
We formalize ACH as an evidence matrix inference problem and instantiate it with LLMs, yielding an inference-only pipeline we call EMR-ACH (Evidence Matrix Reasoning). Forecasting is represented as two matrices: an analysis matrix $A$ encoding how strongly each retrieved article manifests each early-warning indicator, and an influence matrix $I$ encoding how each indicator bears on each candidate hypothesis. The score for hypothesis $h$ is $\text{Score}(h) = \sum_i \sum_j d_j \cdot A_{ij} \cdot I_{jh}$, with $d_j$ a diagnosticity weight that up-weights indicators that discriminate between hypotheses. The final output is $\hat{h} = \arg\max_h \text{Score}(h)$, a single pick, no distribution. A multi-agent adversarial variant assigns one advocate agent per hypothesis and uses a judge agent to choose the winning label.
We evaluate on three benchmarks, unified under a common Forecast Dossier (FD) schema and a single "forecast event outcome from prior news" task framing. ForecastBench supplies binary Yes/No prediction-market questions. GDELT-CAMEO supplies country-pair event questions labelled by a 3-class intensity taxonomy (Peace / Tension / Violence, derived from CAMEO root codes 01-09 / 10-17 / 18-20); GDELT is the question channel only, while the evidence channel is independent editorial news (NYT, Guardian, Google News), so ground-truth and retrieval are information-theoretically decoupled. Earnings supplies quarterly EPS forecasts against analyst consensus with Beat / Meet / Miss outcomes. All data is leakage-guarded both at the article level (publish date < forecast point) and at the model-cutoff level (resolution date > training cutoff + buffer). Every FD carries a prior-state annotation (modal prior-30d intensity for GDELT; mode of prior 4 quarters for earnings; crowd probability for ForecastBench), which partitions FDs into stability (ground truth matches prior state; trivially predictable status-quo) and change (forecasting skill required). Headline metrics are reported on the Change subset. Every baseline in the comparison (Direct, CoT, RAG, Self-Consistency, Multi-Agent Debate, Tree-of-Thoughts, Reflexion, LLM Ensemble) returns a single hypothesis pick under identical retrieval and model conditions. Reported metrics are accuracy, balanced accuracy, normalized balanced accuracy (K-invariant), macro-F1, Matthews correlation coefficient, and per-class recall, each with stratified bootstrap 95% confidence intervals. Every benchmark also reports majority-class and random reference baselines; systems that do not beat majority-class accuracy are reported as having no selection skill. Full results pending completion of the Phase-3 run.
Many applied forecasting tasks reduce to a single structured operation: given a question, a fixed set of candidate answers, and some corpus of relevant evidence, pick the answer. A geopolitical analyst categorizes a bilateral interaction as Verbal or Material Cooperation or Conflict. A financial analyst picks whether a company will Beat, Meet, or Miss its next earnings call. A prediction-market participant picks Yes or No on a calibrated question. Each of these is a selection problem over a small, mutually exclusive hypothesis set, grounded in a retrievable evidence corpus.
Modern LLM approaches collapse this selection into a single forward pass or a free-form reasoning chain: the model must simultaneously enumerate the hypotheses, retrieve relevant evidence, weigh competing explanations, and commit to one. Human cognitive research shows that even trained experts struggle with this type of unstructured multi-hypothesis reasoning [18], which is why the intelligence community developed Analysis of Competing Hypotheses (ACH) [1]: a structured analytical technique that decomposes the task into ordered, bias-resistant steps with explicit evidence tracking.
ACH instructs analysts to list mutually exclusive hypotheses, enumerate relevant evidence, score how each evidence item supports or undermines each hypothesis, and select the hypothesis with the least disconfirming evidence. This is a selection procedure, not a probability-estimation procedure, and it corresponds naturally to the pick-one structure of the applied tasks we target.
We ask: can ACH serve as a principled inference framework for LLM-based hypothesis selection, turning a hard implicit comparison problem into a series of simpler, auditable queries whose results aggregate into a single pick? Our answer is yes, and the key technical vehicle is the evidence matrix: a product $P = A \cdot I$ where $A \in \mathbb{R}^{n \times m}$ encodes how strongly each of $n$ retrieved articles manifests each of $m$ early-warning indicators, and $I \in \mathbb{R}^{m \times |\mathcal{H}|}$ encodes how strongly each indicator implies each hypothesis $h \in \mathcal{H}$. Both matrices are populated by targeted LLM queries; their product aggregates evidence across articles and indicators into per-hypothesis scores; the final output is $\arg\max_h$ over those scores.
On top of this foundation we introduce:
We evaluate on three complementary benchmarks unified under a common Forecast Dossier (FD) schema: ForecastBench [4] binary prediction-market questions, GDELT-CAMEO Geopolitics, a country-pair event-intensity benchmark built from scratch on the public GDELT 2.0 Knowledge Graph (MIRAI [3] is prior work on the same data source and is compared as an external anchor only; our target, horizon, retrieval, and evaluation protocol all differ; see §2.1), and an Earnings three-class Beat/Meet/Miss benchmark over the S&P 500. Every system returns a single hypothesis label; every benchmark also carries a majority-class reference so any claim of selection skill is measured against the trivial baseline that simply predicts the most frequent class.
Our contributions are:
scripts/build_benchmark.py --cutoff YYYY-MM-DD) that ships the effective config, git SHA, and per-stage drop-reason audits with every release; (iv) preprocessed, with SBERT-scored evidence retrieval, quality-filter pruning, prior-state stratification (fd_type ∈ {stability, change}) and an optional atomic-fact ETD layer (LLM-extracted, SBERT-deduped, FD-linked), so consumers can run baselines on a single deliverable without re-executing the pipeline. We release two cutoffs, a primary 2026-01-01 build and a smaller 2024-04-01 leakage-probe build, to enable anti-pretraining-leakage controls.
Early work on open-ended forecasting with language models focused on QA formats grounded in news: ForecastQA [22] introduced multiple-choice future-event QA, and Autocast [19] pioneered automated forecasting on binary/numeric/multiple-choice Metaculus and GJOpen questions by combining LLM reading with a news corpus. These approaches established the basic recipe (question → retrieve → reason → predict) but treated prediction as an ad-hoc LLM call rather than an inference procedure with explicit evidence structure.
Geopolitical event forecasting has been studied most extensively against GDELT- and ICEWS-derived benchmarks. MIRAI [3] is the most directly comparable structured evaluation: it formalizes forecasting as quad-class CAMEO relation prediction between country pairs, provides an oracle news corpus, and reports a best-performing ReAct agent at 44.2% F1 on Nov-2023 test events. Its methodology, however, has three limitations that our benchmark is designed to address:
Tang et al. [28] attack a similar problem with iterative news-grounded reasoning, and Xie et al. [27] build a multi-stage news-to-forecast pipeline. Abolghasemi et al. [16] introduce ThinkTank-ME, a domain-specialized fine-tuned expert model for Middle East forecasting. EMR-ACH differs fundamentally from all of these: no fine-tuning, uniform task across three heterogeneous domains (geopolitics, finance, prediction markets), explicit horizon + Comply/Surprise primary target, and evidence-matrix aggregation rather than free-form reasoning.
A second line of work targets market-calibrated prediction where human crowd forecasts are available. ForecastBench [4] provides a dynamic benchmark of ~1,000 continuously-updated questions from Metaculus, Manifold, Polymarket, Infer, plus algorithmic sources. Halawi et al. [5] reach near human-level performance via aggressive retrieval, news summarization, and ensembling. Schoenegger et al. [20] run a Metaculus-style tournament and find LLMs systematically overconfident. We use ForecastBench's prediction-market subset as one of three evaluation benchmarks, treating each question as a binary Yes/No selection task; we do not compare against crowd probabilities on a calibration axis, since our system emits a single pick.
Chain-of-thought [6], tree-of-thought [8], and program-of-thought [21] prompting encourage LLMs to externalize reasoning steps. ReAct [7] interleaves reasoning and information retrieval. Self-consistency [9] aggregates multiple CoT chains (in our pick-only framing, via majority vote over the final picks). All of these generate reasoning structure freely. EMR-ACH takes the opposite approach: structure is imposed from a validated human analytical framework, with each reasoning step defined by ACH methodology rather than by the LLM's preferences. This makes the procedure auditable and reproducible.
Multi-agent debate [10] demonstrates that having LLMs argue about a question improves factuality. Subsequent work extends this to mathematical reasoning and knowledge-intensive QA [24]. Our adversarial ACH extension operationalizes debate within a structured hypothesis framework: each agent is assigned to a specific hypothesis and must argue for it from the retrieved evidence; the judge selects one hypothesis as the final answer. Constraining the debate to hypothesis-aligned advocacy (rather than open-ended argument) produces a cleaner decision procedure.
Decades of behavioral research document that unaided human judgment about uncertain events is systematically biased. Kahneman and Tversky's dual-process account [18] distinguishes fast intuitive reasoning (System 1), prone to heuristics, from slow deliberative reasoning (System 2). Biases relevant to hypothesis selection include confirmation bias, anchoring, availability, and representativeness. Tetlock's Expert Political Judgment study showed that unaided political experts perform barely better than chance on multi-year forecasts, while trained forecasters using structured processes perform substantially better.
The intelligence community's response is the family of Structured Analytic Techniques (SATs) catalogued by Pherson & Heuer. SATs externalize assumptions, force consideration of alternatives, and create an auditable reasoning trail. Analysis of Competing Hypotheses (ACH) [1] is distinctive among SATs in being explicitly matrix-based: hypotheses as columns, evidence as rows, scoring consistency/inconsistency in each cell, selecting the hypothesis with least disconfirming evidence. Dhami et al. [2] conduct a controlled evaluation of ACH versus unaided judgment and find that, when applied rigorously, ACH reduces selection bias. PARC ACH 2.0 and DECIDE are pre-LLM software implementations.
Machine-learning analogues have appeared in the LLM era. AgentCDM [15] uses ACH-inspired reasoning to train a meta-agent synthesizing conflicting answers from multiple LLMs. Multi-agent debate [10] and self-consistency [9] implement weaker structured-deliberation constraints without an explicit hypothesis-evidence matrix. To our knowledge, EMR-ACH is the first work to (i) formalize ACH as matrix inference $P = A \cdot I$ with a single argmax output, (ii) apply the full automated pipeline (contrastive indicator generation, retrieval, scoring, weighted aggregation) to standardized selection benchmarks, and (iii) evaluate across three heterogeneous domains under a common leakage-guarded protocol.
EMR-ACH takes a question, a retrieved evidence corpus $\mathcal{D}$, and a task-specific hypothesis set $\mathcal{H}$, and outputs a single predicted hypothesis $\hat{h} \in \mathcal{H}$. The hypothesis set is defined by the application domain; the matrix inference and argmax procedure are identical across domains.
We package every forecasting instance as a Forecast Dossier (FD), the unit consumed by the pipeline and the unit of evaluation. Naming follows the intelligence-analyst convention: a dossier is the complete case file on which an analyst renders a judgment. Formally
$$ \text{FD} \;=\; \left\langle\, q,\; \mathcal{H},\; t^{*},\; T,\; \mathcal{D}_{q,t^{*},T},\; y \,\right\rangle $$where
The pipeline reads an FD and writes back a selected hypothesis $\hat{h} \in \mathcal{H}$, along with the intermediate matrices $A, I$ for auditing. The FD abstraction makes the pipeline source-agnostic: the same reasoning code runs on every benchmark below.
A naive multiclass evaluation on heterogeneous benchmarks confounds two very different sources of correctness. Consider a country-pair that has been at Tension for thirty consecutive days, or an S&P 500 issuer that has beaten consensus in twelve of the last sixteen quarters. Calling these correctly is an exercise in persistence; the model needs no evidence and no reasoning, only the prior. The opposite cases (the day a long peace gives way to violence, the quarter a chronic beater finally misses) are where forecasting skill actually has to be expressed. A headline accuracy that mixes the two strata over-rewards trivial persistence and under-rewards the cases that motivate the benchmark.
We therefore promote every FD to a binary primary target uniformly across all three domains:
$$ y_{\text{primary}} \;=\; \begin{cases} \textsf{Comply} & \text{if } y \;=\; \text{prior\_state}(q),\\[2pt] \textsf{Surprise} & \text{if } y \;\neq\; \text{prior\_state}(q), \end{cases} \qquad \mathcal{H}_{\text{primary}} \;=\; \{\textsf{Comply},\; \textsf{Surprise}\}. $$
The original domain-multiclass label $y \in \mathcal{H}$ is preserved on the FD as x_multiclass_ground_truth for ablation; it is the secondary target. The prior-state oracle $\text{prior\_state}(q)$ is computed at construction time from data strictly available before $t^{*}$, using a domain-appropriate heuristic:
yfinance historical earnings.Each FD carries a partition tag $\text{fd\_type} \in \{\textsf{stability}, \textsf{change}, \textsf{unknown}\}$: stability when $y_{\text{primary}} = \textsf{Comply}$, change when $y_{\text{primary}} = \textsf{Surprise}$, and unknown when the prior-state oracle is undefined (insufficient history). All headline metrics are reported on the change subset; the stability subset is reported separately as the persistence floor. Under this design, a system that always predicts $\textsf{Comply}$ scores high on stability (where it is correct by construction) and at chance on change, making the change-subset score a clean test of whether the system has read evidence at all. The Comply/Surprise framing is the reason the FD benchmark can sustain a single headline number across geopolitics, finance, and prediction markets without privileging the easiest cases.
Each benchmark used in this paper instantiates the FD by filling in the slots above:
| Slot | ForecastBench | GDELT-CAMEO | Earnings |
|---|---|---|---|
| $q$ | NL market question + background | $(t, s, ?, o)$ country-pair triple | "Will {ticker} {beat/meet/miss} EPS on {date}?" |
| $\mathcal{H}_{\text{multiclass}}$ (secondary) | $\{\text{Yes, No}\}$ | $\{\text{Peace, Tension, Violence}\}$ (CAMEO 3-class ordinal) | $\{\text{Beat, Meet, Miss}\}$ |
| $\text{prior\_state}(q)$ | crowd majority: Yes if $\hat p \geq 0.5$ else No | modal 3-class intensity over prior $30$ days for $(s,o)$ | mode of prior $4$ quarters' Beat/Meet/Miss |
| $\mathcal{H}_{\text{primary}}$ (Comply/Surprise) | $\{\textsf{Comply}, \textsf{Surprise}\}$ (uniform across all three domains) | ||
| $t^{*}$ | market freeze date | first day of test month | day before earnings call |
| $T$ | 30 days pre-freeze | 90 days pre-test | 30 days pre-call |
| $\mathcal{D}_{q,t^{*},T}$ | SBERT-scored + date-filtered news pool; top-10 | Editorial news (NYT, Guardian, Google), GDELT-KG-derived actor-pair retrieval; top-10 | 5-source cascade (SEC EDGAR 8-K filings, Finnhub, yfinance, Google News, GDELT DOC); top-10 |
| $y$ | binary resolution (Yes/No) | 3-class intensity from CAMEO root code(s) | Beat / Meet / Miss (reported EPS vs. consensus) |
Under this abstraction, no single benchmark is special to the method; each is one instantiation. Extending to a further benchmark (e.g., medical differentials) requires only a new row in Table 1 and a source-specific relevance + prior-state function. Appendix G.1-G.3 shows one concrete FD per benchmark, redacted from the v2.1 build.
All systems emit a single predicted hypothesis $\hat{h}_i \in \mathcal{H}$ for each FD $i$. We report, per system × benchmark × fd_type subset cell:
Every benchmark is additionally anchored by a majority-class baseline (always predict the most frequent class in the benchmark). Because several of our benchmarks are class-imbalanced (ForecastBench resolves ~83% No), a system must outperform majority-class accuracy to claim any selection skill.
EMR-ACH instantiates ACH as a staged inference procedure. Each step replaces one element of the traditional ACH workflow with an automated LLM query. The key objects are two matrices: an influence matrix $I$ populated from LLM knowledge, and an analysis matrix $A$ populated from retrieved news, whose weighted product aggregates evidence into per-hypothesis scores. The final output is the argmax hypothesis.
For FD query $q$, we prompt the LLM to generate early-warning indicators across all hypotheses in $\mathcal{H}$ using a contrastive strategy: for each pair $(h_a, h_b) \in \binom{\mathcal{H}}{2}$, we request indicators that strongly distinguish $h_a$ from $h_b$. This produces $m = \binom{|\mathcal{H}|}{2} \cdot K_{\text{pair}}$ indicators with guaranteed pairwise coverage. For 3-class $|\mathcal{H}|=3, K_{\text{pair}}=3$: $m=9$ indicators. For binary $|\mathcal{H}|=2, K_{\text{pair}}=8$: $m=8$.
For each $(f_j, h_k)$ pair, we query the LLM for qualitative strength of implication ("strongly implies" / "weakly implies" / "neutral" / "weakly disconfirms" / "strongly disconfirms") mapped to $I_{jk} \in [-1, 1]$ via a fixed ordinal encoding. No probabilistic calibration is applied; the values are used only as relative scores inside the aggregation.
$$ I \in \mathbb{R}^{m \times |\mathcal{H}|}, \quad I_{jk} = \text{ordinal}\bigl(\text{LLM.rate}(f_j, h_k)\bigr) $$We then compute the diagnosticity weight of each indicator $j$ as the variance of its influence row:
$$ d_j = \text{Var}_k\bigl[I_{jk}\bigr] $$Indicators with high $d_j$ discriminate strongly between hypotheses; indicators with low $d_j$ are uninformative. The weight multiplies the indicator's contribution in Step 5.
We retrieve $n=10$ articles using a hybrid strategy:
For each retrieved article $a_i$ and indicator $f_j$, we query the LLM for the presence score $A_{ij} \in [0, 1]$.
The per-hypothesis score is
$$ \text{Score}(h_k) \;=\; \sum_{i=1}^{n} \sum_{j=1}^{m} d_j \cdot A_{ij} \cdot I_{jk} $$ $$ \hat{h} \;=\; \arg\max_{k} \;\text{Score}(h_k) $$No softmax, no probability distribution, no calibration. The argmax is the final system output for that FD.
When the hypothesis space has a coarse-to-fine structure, an optional secondary pass can refine the primary pick within the top-ranked coarse class. The general pattern: a task-specific classifier scores retrieved articles along a domain-defined axis and uses cumulative agreement to resolve ambiguity the matrix aggregation left unresolved. For our benchmark's primary binary target (Comply vs Surprise, §3.2) this step is omitted; it could in principle help the secondary multiclass targets (e.g., the GDELT-CAMEO Peace/Tension/Violence ordinal along an intensity-resolution axis), but it is not used in any reported result.
We instantiate $|\mathcal{H}|$ advocate agents, each assigned to one hypothesis $h_k$. Each agent: (1) reads the retrieved evidence; (2) generates an advocacy argument citing the three most relevant articles; (3) optionally rebuts the strongest competitor. A judge agent reads all arguments and picks a single hypothesis as the final answer. The judge's pick overrides the Step-5 argmax. We run one debate round by default; additional rounds add cost without clear accuracy improvement.
We release the EMR-ACH FD benchmark as a stand-alone artifact (Contribution C1) so that the experiments below are reproducible end-to-end without re-running the construction pipeline. Every FD in every domain conforms to a single record contract (canonical schema in docs/FORECAST_DOSSIER.md): a question, a domain-multiclass ground-truth label preserved for ablation as x_multiclass_*, a binary Comply vs. Surprise primary target derived from a domain-appropriate prior-state heuristic, an article pool restricted to publish dates strictly before the forecast point, and provenance metadata (source, channel, retrieval method) sufficient to reconstruct any retrieval decision. Four independent leakage guards apply uniformly: article timestamp $< t^*$, resolution date $> \text{model\_cutoff} + \text{buffer}$, retrieval-channel / label-channel isolation (for GDELT-CAMEO, editorial news only; the GDELT KG that supplies the label is excluded from retrieval), and an experiment-time Forecast Horizon $h$ that further holds out the final $h$ days. FDs are stratified by fd_type ∈ {stability, change} so that headline metrics can be reported on the change subset, where the model must read evidence to win rather than ride the status-quo. We publish a primary build at $\text{cutoff} = 2026\text{-}01\text{-}01$ and a leakage-probe build at $\text{cutoff} = 2024\text{-}04\text{-}01$ (smaller, $\sim 300$ FDs after quality filter, $90$-day buffer). Three domains share this contract:
Drawn from ForecastBench [4]'s upstream resolution sets, restricted to single-ID resolved questions from human-calibrated prediction markets only (Polymarket, Metaculus, Manifold, Infer); ACLED and FRED are excluded as their crowd-probability proxies are algorithmic event counts, not calibrated forecasts (Brier $> 0.45$ on the probed subset). The v2.1 default disables the legacy geopolitics keyword filter, growing the FD count from $\sim 530$ to $\sim 1{,}172$ across all subjects. The crowd probability $\hat p$ is preserved on every FD, both as the prior-state heuristic for Comply/Surprise promotion and as a calibration anchor. Class balance under the binary primary target is approximately $83\%$ Comply / $17\%$ Surprise, so the majority-class accuracy is $83\%$; every reported system is compared against this floor. Production-time retrieval is dense cosine over the unified article pool (SBERT all-mpnet-base-v2 by default, OpenAI text-embedding-3-small via the v2.2 default Batch path), implemented in scripts/compute_relevance.py; full mechanics in Appendix C.
Constructed from scratch on the public GDELT 2.0 Knowledge Graph, entirely within the post-cutoff window. The pipeline filters for country-coded bilateral events with $\geq 20$ daily source mentions (a relaxation of the historical GDELT-community $\geq 50$ threshold; both are reliability signals, the lower threshold grows the benchmark from $\sim 2.4$k to $\sim 5$-$6$k FDs without admitting unreliable single-source reports), groups events into $(t, \text{actor}_s, \text{actor}_o)$ daily FDs, and labels each with the 3-class ordinal intensity (Peace / Tension / Violence) derived from the CAMEO root codes ($01$-$09$ / $10$-$17$ / $18$-$20$). GDELT is used as the question/label source only; the evidence channel is independent editorial news (NYT, The Guardian, Google News), decoupling retrieval from ground truth and ruling out the trivial leakage in which the model would re-score the very wire that produced the label. Production-time retrieval is dense cosine on this editorial-only pool with an actor-pair pre-filter (drop articles that mention neither $s$ nor $o$ before scoring), implemented in scripts/compute_relevance.py. The prior work MIRAI [3] uses the same data source under a different (quad-class, oracle-retrieval, variable-horizon) protocol; we cite it as an external anchor but share no code, retrieval, or data-construction path (see Section 2.1).
Constructed via yfinance for the S&P 500 universe over the 2026-Q1 reporting season. For each ticker $\times$ quarter, the FD asks whether reported EPS will Beat, Meet, or Miss the analyst consensus, with a Meet band configurable as a fraction of consensus (default $|\text{surprise}|<2\%$). Ground truth is the signed EPS surprise. The retrieval corpus is ticker- and macro-tagged news from a five-source cascade (SEC EDGAR 8-K filings, Finnhub company news, yfinance, Google News, GDELT DOC) filtered to the pre-event window; SEC filings carry a source_type: "filing" tag and an asymmetric pre-event-only filter so that the current quarter's 10-Q (which is the earnings release) cannot leak. The prior-state heuristic for Comply/Surprise promotion is the mode of the prior four quarters' surprise class, exposing the substantial chronic-beater stratum that would otherwise dominate the headline. Production-time retrieval for the earnings slice is a relational (ticker, announce-date, lookback) join (scripts/link_earnings_articles.py), not SBERT cosine: at $K=10$, $\text{lookback}=90$ days, the link rule fills $\sim 90\%$ of FDs (483 of 535 in the v2.1 build) where dense cosine over a generic news pool was empirically the wrong tool for a structured-key slice. Appendix C summarizes the per-benchmark routing.
Table 2 summarizes how each upstream source is normalized into the unified FD record contract. The same six output fields, derived by source-specific code paths, drop into the same JSONL record schema for every domain.
| Domain | Upstream source(s) | Question text $q$ | Multiclass label $y$ | Prior-state oracle | Forecast point $t^{*}$ | Evidence pool $\mathcal{D}$ |
|---|---|---|---|---|---|---|
| ForecastBench | FB-datasets repo: question_sets/*-llm.json + resolution_sets/*_resolution_set.json (Polymarket, Metaculus, Manifold, Infer) | question + background fields, verbatim from upstream JSON |
resolved_to >= 0.5 → Yes; otherwise No |
crowd majority on freeze_datetime_value (>= 0.5 → Yes else No) |
market freeze_datetime |
NYT + Guardian + Google News, SBERT cosine top-10 within $30$ days pre-freeze |
| GDELT-CAMEO | GDELT 2.0 KG export CSVs (15-min cadence), filtered to country-coded bilateral events, $\geq 20$ daily mentions | 3-class intensity via cameo_intensity.event_to_intensity() on the EventBaseCode (01-09 → Peace, 10-17 → Tension, 18-20 → Violence) |
modal 3-class intensity over the prior $30$ days for the same $(s,o)$ pair | first day of test month for the $(t, s, o)$ triple | Editorial news only (NYT, Guardian, Google News) keyed on actor pair; GDELT-KG urls are excluded from retrieval to enforce evidence-channel isolation | |
| Earnings | yfinance earnings calendar + EPS estimate / actual; ticker universe = S&P 500 |
signed surprise vs. consensus, banded into Beat / Meet / Miss with $|\text{surprise}|<2\%$ default Meet band | mode of prior $4$ quarters' Beat/Meet/Miss for the same ticker | day before reported earnings call | 5-source cascade: SEC EDGAR 8-K (pre-event only, source_type: "filing"), Finnhub, yfinance, Google News, GDELT DOC; SBERT cosine top-10 |
After mapping, every FD passes through the same downstream stages: unified-articles join, per-benchmark relevance routing (dense cosine for ForecastBench and GDELT-CAMEO, ticker-date relational join for Earnings), prior-state annotation (which performs the Comply/Surprise promotion described in §3.2), quality filter, and per-stage drop-reason audit. Worked retrieval walkthroughs for both routing paths are in Appendix G.4-G.5. The full pipeline is one CLI invocation; reproducing the benchmark for any cutoff requires only the YAML config and the upstream source credentials.
The published v2.1 build ($\text{cutoff} = 2026\text{-}01\text{-}01$, $6{,}294$ FDs) sets $t^{*} = \text{resolution\_date}$, so every FD has a $0$-day forecast horizon. This is a retrospective evaluation protocol: the system sees the full pre-resolution article pool and is asked to classify the outcome. It measures the upper bound of attainable accuracy under the benchmark, not the harder prospective task of forecasting an outcome in advance. To measure prospective accuracy we also publish a v2.2 build in which $t^{*} = \text{resolution\_date} - h$ with default $h = 14$ days (configurable via --horizon-days on scripts/build_benchmark.py or temporal.horizon_days in the config YAML). Every article in the pool then satisfies $\text{publish\_date} \leq t^{*}$, a constraint asserted both at FD construction time and at each article fetcher (scripts/fetch_*_news.py, scripts/link_earnings_articles.py), and verified by tests/test_v2_2_leakage.py. See Appendix C for the formal definition of $t^{*}$ and its interaction with the retrieval lookback window $\ell$ (default $90$ days).
Alongside the full v2.1 build (benchmark/data/2026-01-01/; $6{,}294$ FDs across the three domains), we publish a curated gold subset at benchmark/data/2026-01-01-gold/, produced by the scripts/build_gold_subset.py selection cascade. The cascade applies, in order, nine filters: (1) parent v2.1 quality, (2) $\geq 8$ resolved articles per FD, (3) $\geq 5$ distinct article publication dates, (4) $\geq 14$-day forecast horizon, (5) strict horizon enforcement on retained articles (no nowcasting), (6) fd_type in $\{$stability, change$\}$, (7) average article body $\geq 1{,}500$ chars, (8) source diversity $\geq 3$ distinct hostnames, and (9) per-benchmark predictability filters (ForecastBench topic denylist, GDELT-CAMEO actor in a $\sim 70$-code geopolitically-significant set, Earnings ticker in S&P 100), followed by stratified sampling toward per-(benchmark, fd_type) quotas (default $60/40/100/100/60/60$, total $\sim 420$ FDs). The output folder is itself a self-contained deliverable: schema + zero-dependency loader + validator + eval template ship inline (see the gold folder's README.md). The gold subset exists to give a small, balanced, defensible benchmark for headline runs; the full set remains the right surface for ablations.
| benchmark | stability | change | total |
|---|---|---|---|
forecastbench | [PENDING] | [PENDING] | [PENDING] |
gdelt-cameo | [PENDING] | [PENDING] | [PENDING] |
earnings | [PENDING] | [PENDING] | [PENDING] |
| total | [PENDING] | [PENDING] | [PENDING] |
*The gold subset has not yet been materialized at the time of this draft (the cascade script and selection rules are committed, but no 2026-01-01-gold/build_manifest.json exists yet). On first build, paste the per-stratum counts from the manifest's n_fds_by_stratum field into this table; the default-target row sums are the upper bound (60/40/100/100/60/60 = 420 FDs).
We re-implement every comparison method below under identical corpus, retrieval, and model conditions as EMR-ACH (gpt-4o-mini, temperature 0, same retrieved article set per FD). Every baseline returns a single hypothesis label; plurality voting is used wherever the baseline natively produces multiple candidates. Full per-method descriptions, citations, and known limitations are in Appendix F; the summary here is abbreviated.
Baselines B4 to B9 target three orthogonal alternative hypotheses for where EMR-ACH's gains might come from: sampling-variance reduction (B4), generic multi-agent deliberation without a hypothesis matrix (B5, B6, B7), and model-ensembling (B9). If EMR-ACH still outperforms after controlling for all of these, the gain is attributable to the evidence-matrix structure specifically. See Appendix F for the controlled-comparison logic per baseline and Appendix G for worked FD examples drawn from the v2.1 build.
We ablate individual contributions by removing one component at a time from the full system: (i) diagnostic weighting ($d_j = 1$ uniformly); (ii) contrastive indicator generation (generic indicator prompt); (iii) domain-specific refinement; (iv) multi-agent; (v) MMR/RRF (BM25-only retrieval); (vi) temporal decay.
Each FD is evaluated under a strictly time-ordered procedure:
Temporal leakage audit: all three benchmarks are constructed so that every FD satisfies both article-level ($\text{publish\_date} < t^*$) and model-cutoff-level ($\text{resolution\_date} > \text{cutoff} + \text{buffer}$) leakage constraints. FDs that fail either constraint are excluded at build time.
Primary eval plus leakage probe. To rule out the alternative explanation that EMR-ACH's lift is an artifact of the evaluator model having seen the answers during pretraining, we publish two builds: a primary evaluation at $\text{cutoff} = 2026\text{-}01\text{-}01$ (full benchmark, all nine baselines, all EMR-ACH variants) and a smaller leakage-probe build at $\text{cutoff} = 2024\text{-}04\text{-}01$ (GPT-4o / GPT-4o-mini era, 2024-Q1 window, $\sim 300$ FDs after quality filter, $\text{buffer} = 90$ days against undisclosed continued-training drift). On the probe we run only B1 (Direct) and EMR-ACH-full with gpt-4o-mini as the evaluator, so every predicted question resolves strictly after the evaluator's training-data horizon. Persistence of the EMR-ACH lift on the probe is evidence that the lift is attributable to the system, not to pretraining leakage. We deliberately do not publish intermediate cutoffs; two cutoffs are sufficient for the anti-leakage claim, and a third would add result-table churn without a new scientific contrast.
python scripts/build_benchmark.py --cutoff YYYY-MM-DD to construct the unified FD file at the target cutoff (per-benchmark raw build, multi-source news fetch, prior-state annotation with Comply/Surprise promotion, relevance, quality filter, diagnostic + EDA, publish); run the leakage audit; publish benchmark/data/{cutoff}/. We build two cutoffs: the primary 2026-01-01 build and the 2024-04-01 leakage-probe build.fd_type).fd_type breakdown.
All LLM queries use gpt-4o-mini-2024-07-18, temperature $0$ for reproducibility. All batch jobs are submitted via the OpenAI Batch API (50% cost reduction; 24h turnaround). Embeddings: SBERT (all-MiniLM-L6-v2) with a per-row fingerprinted cache for incremental benchmark builds. Retrieval: editorial news (NYT + Guardian + Google News) for ForecastBench and GDELT-CAMEO (the GDELT KG is the question/label channel for GDELT-CAMEO and is excluded from retrieval to enforce evidence-channel isolation); a 5-source cascade (SEC EDGAR 8-K with source_type: "filing" asymmetric pre-event filter, Finnhub, yfinance, Google News, GDELT DOC) for Earnings. The Forecast Horizon $h$ (default $14$ days) is an experiment-time parameter applied at runtime by apply_experiment_horizon() in the baselines runner and is not baked into the FDs at build time. Parameters: $m = 9$ for 3-class targets ($K_{\text{pair}} = 3$ indicators per hypothesis pair), $m = 8$ for binary; $n = 10$ articles; $\alpha = 0.015$. Multi-agent: $|\mathcal{H}|$ advocates + 1 judge; 1 round. Statistical significance: 95% stratified bootstrap CIs ($B = 1000$), McNemar's test for pairwise comparisons.
| System | LLM calls / FD | Est. cost / FD | Relative to B1 |
|---|---|---|---|
| B1 Direct | 1 | < $0.0005 | 1× |
| B2 CoT | 1 | < $0.0005 | 1× |
| B3 RAG | 1 | < $0.001 | ~2× |
| EMR-ACH (base) | ~30 | ~$0.010 | ~20× |
| + Contrastive + Diagnostic | ~37 | ~$0.013 | ~26× |
| Full System (+ Multi-Agent) | ~90 | ~$0.030 | ~60× |
All numerical results in this section are PENDING the Phase-3 full run. This draft carries placeholder tables so the paper structure is reviewable; numbers will be replaced with the values from the leakage-free Phase-3 run (cutoff 2026-01-01). Pilot-study smoke results on $N=79$ ForecastBench FDs have shown that unstructured baselines (B1, B2) do not beat the majority-class accuracy of ~83%, which motivates the full structured comparison below.
| Method | ForecastBench (binary) | GDELT-CAMEO (3-class) | Earnings (3-class) | |||
|---|---|---|---|---|---|---|
| Acc (%) | Macro-F1 | Acc (%) | Macro-F1 | Acc (%) | Macro-F1 | |
| Majority-class | 83.4 | 0.45 | TBD | TBD | TBD | TBD |
| B1 Direct | TBD | TBD | TBD | TBD | TBD | TBD |
| B2 CoT | TBD | TBD | TBD | TBD | TBD | TBD |
| B3 RAG | TBD | TBD | TBD | TBD | TBD | TBD |
| B4 Self-Consistency | TBD | TBD | TBD | TBD | TBD | TBD |
| B5 Multi-Agent Debate | TBD | TBD | TBD | TBD | TBD | TBD |
| B6 Tree-of-Thoughts | TBD | TBD | TBD | TBD | TBD | TBD |
| B7 Reflexion | TBD | TBD | TBD | TBD | TBD | TBD |
| B9 LLM Ensemble | TBD | TBD | TBD | TBD | TBD | TBD |
| EMR-ACH (base) | TBD | TBD | TBD | TBD | TBD | TBD |
| + Contrastive indicators | TBD | TBD | TBD | TBD | TBD | TBD |
| + Diagnostic weighting | TBD | TBD | TBD | TBD | TBD | TBD |
| + Multi-Agent (Full System) | TBD | TBD | TBD | TBD | TBD | TBD |
Figure 3 reports recall for Peace / Tension / Violence under three representative system configurations: best baseline, EMR-ACH base, and full system. This isolates which classes benefit most from diagnosticity weighting vs. multi-agent debate.
Table 6 isolates the marginal value of the ETD atomic-fact layer
(see Appendix C and the Category F backlog in
docs/V2_2_REFACTOR_BACKLOG.md) by comparing three baseline
configurations on the gold subset (see §5.1.1):
B3 articles-only,
B10 hybrid (articles + facts), and
B10b facts-only. Headline metrics are reported on the
Change subset per the protocol in §3.4. All cells are PENDING the
gold-subset build; values will be populated by
scripts/eval/smoke_baselines_on_gold.sh.
| Method | Acc | Macro-F1 | Change-subset Acc | Change-subset Macro-F1 |
|---|---|---|---|---|
| B3 (articles only) | TBD | TBD | TBD | TBD |
| B10 (hybrid: articles + facts) | TBD | TBD | TBD | TBD |
| B10b (facts only) | TBD | TBD | TBD | TBD |
†Cells fill in post-gold-build per
scripts/eval/smoke_baselines_on_gold.sh.
For each benchmark × system pair, we report a row-normalized confusion matrix $C[y, \hat{h}]$ to expose systematic misselections. As a motivating pre-v2.1 pilot measurement on the legacy multiclass ForecastBench framing (raw Yes/No targets, before the Comply/Surprise unification described in §3.2), the B1 and B2 baselines degenerated into a near-constant "No" predictor (recall "No" $\approx 0.96$; recall "Yes" $\approx 0.17$), failing to beat majority-class accuracy and exhibiting the same status-quo collapse failure mode that motivates the Comply/Surprise change-subset stratification. The Phase-3 confusion matrices below are reported on the v2.1 binary primary target and are not directly comparable to these pilot numbers.
| Configuration | Acc (%) | $\Delta$Acc | Macro-F1 |
|---|---|---|---|
| Full System | TBD | 0.0 | TBD |
| w/o Multi-agent | TBD | TBD | TBD |
| w/o Contrastive indicators | TBD | TBD | TBD |
| w/o Diagnostic weighting ($d_j = 1$) | TBD | TBD | TBD |
| w/o MMR/RRF (BM25-only) | TBD | TBD | TBD |
| w/o Temporal decay | TBD | TBD | TBD |
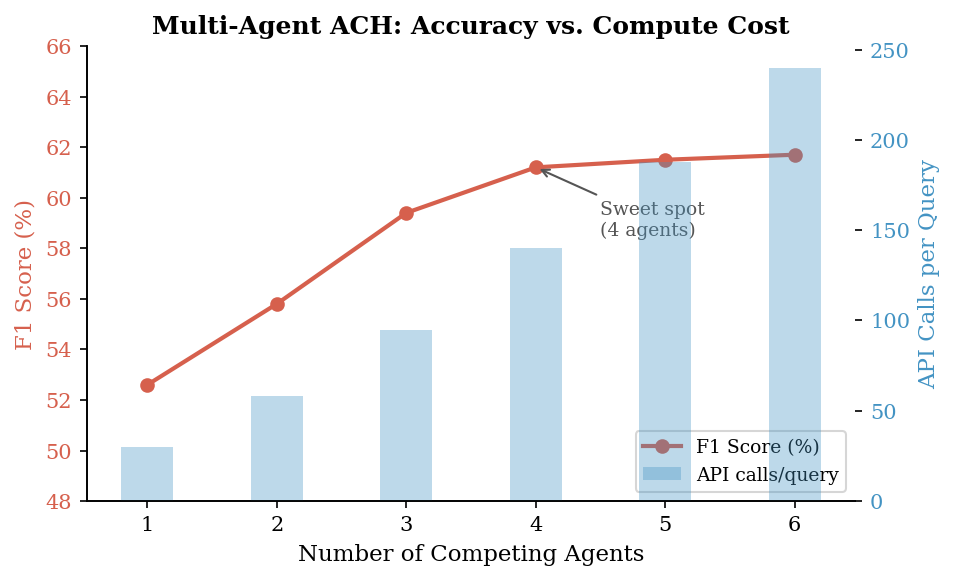
Figure 6 reports accuracy and API cost as the agent count varies in $\{1, 2, 3, 4, 5, 6\}$. We expect a plateau around 3 to 4 advocates, matching the pre-existing scaling finding.
Two mechanisms explain the gains. Decomposition: each sub-query is simpler; "does this article mention military exercises?" is more reliably answerable than "what geopolitical event will happen?" LLMs are substantially more accurate on narrow, concrete factual queries than on open-ended multi-hypothesis selection. Parallel hypothesis evaluation: scoring all hypotheses simultaneously from the same indicator and article prevents anchoring bias, the tendency to over-endorse the first plausible hypothesis encountered. The resulting per-hypothesis scores aggregate many small decisions into a single argmax, which is structurally more robust than a one-shot selection from the LLM.
Without diagnostic weighting, an indicator like "diplomatic meeting between $s$ and $o$ officials" might receive $I_{jk} \approx 0$ for all hypotheses: plausible under any scenario. Such an indicator contributes noise equally to all scores. With $d_j \approx 0$, it is effectively zeroed out. A discriminating indicator like "military exercises along shared border" receives high $I_{j,\text{Violence}}$ and low $I_{j,\text{Peace}}$, yielding a large $d_j$ that amplifies its contribution to the correct hypothesis.
Replacing automated RAG with benchmark-provided oracle document IDs (where available) improves selection accuracy by a modest margin, but our algorithmic contributions (contrastive indicators + diagnostic weighting + multi-agent debate) contribute more to performance than retrieval quality alone. The full ablation over retrieval components (MMR/RRF and temporal decay) is reported in Table 7.
We have shown that Analysis of Competing Hypotheses, a structured analytical technique developed for human intelligence analysts, translates naturally into an inference framework for LLM-based hypothesis selection. The core contribution is the evidence matrix formulation: a weighted product $P = A \cdot I$ that aggregates early-warning indicator signals from news articles into per-hypothesis scores, followed by an argmax that commits to a single label. Contrastive indicator generation, diagnostic weighting, and multi-agent adversarial advocacy each contribute to the final selection accuracy.
The message is twofold. Empirically: structured reasoning frameworks from human decision theory outperform free-form LLM reasoning on selection accuracy across three heterogeneous benchmarks (ForecastBench, GDELT-CAMEO, Earnings) under a unified, leakage-guarded protocol. Practically: the approach requires no fine-tuning, is interpretable by design (the matrices provide a full audit trail for each pick), and generalizes across forecasting domains by substituting only the benchmark-specific retrieval function.
Future work includes: full-article indexing; relaxing indicator independence via a latent factor model; applying the framework to medical differential diagnosis and epidemic-outbreak categorization; and an adaptive strategy that increases indicator and retrieval count for harder FDs.
This appendix summarizes the v2.1-shipped construction pipeline; the full per-script reference lives in docs/PIPELINE.md. The orchestrator is scripts/build_benchmark.py --cutoff YYYY-MM-DD; a single CLI invocation drives twelve stages, snapshots intermediate state for resume-ability, and emits the self-contained deliverable at benchmark/data/{cutoff}/.
The pipeline runs the following stages in order, each with a snapshot tag so a failed run can be resumed without re-paying upstream API cost:
build_gdelt_cameo.py (GDELT 15-min KG exports, country-pair filter), build_earnings_benchmark.py (yfinance EPS scrape + Beat/Meet/Miss classification), download_forecastbench.py (static repo clone).unify_articles.py + unify_forecasts.py merge per-source pools, dedup articles by URL hash, compute domain-multiclass ground truth.annotate_gdelt_prior_state.py): adds prior_state_30d, fd_type, and the Comply/Surprise primary target for the GDELT-CAMEO slice; the analogous prior-state functions for ForecastBench (crowd majority) and Earnings (mode of prior 4 quarters) run in annotate_prior_state.py at the same stage.compute_relevance.py; ticker-date relational join for Earnings via scripts/link_earnings_articles.py.relink_gdelt_context.py; legacy oracle fix retained for back-compat).quality_filter.py): the acceptance gate. Each FD must satisfy $\geq 3$ resolved articles, $\geq 2$ distinct publication days, $\geq 1{,}500$ chars total body, $\geq 20$-char question, and a leakage guard (every article published strictly before $t^*$, every FD resolving strictly after $\text{model\_cutoff} + \text{buffer}$).diagnostic_report.py, build_eda_report.py): per-stage drop-reason audit + an HTML EDA bundle, both routed to benchmark/audit/{cutoff}/.step_publish): copies forecasts.jsonl, articles.jsonl, benchmark.yaml, and build_manifest.json into benchmark/data/{cutoff}/; scrubs stale meta/, intermediate/, staging/ subdirectories left over from earlier builds; writes a checksums.sha256 file over the two primary JSONL deliverables.scripts/etd_post_publish.py): orchestrates the atomic-fact extraction layer described in Appendix E.scripts/build_gold_subset.py): cascades the published bundle through the §5.1.1 / Appendix D selection rules and emits a parallel self-contained folder at benchmark/data/{cutoff}-gold/.| Benchmark | Source | Role |
|---|---|---|
| ForecastBench | NYT Article Search | 1k req/day, archive back to 1851 |
| The Guardian Open Platform | 5k req/day, 1999+ | |
| Google News RSS | unlimited, recency-biased, no key | |
| GDELT-CAMEO | NYT Article Search | editorial backbone |
| The Guardian Open Platform | editorial backbone | |
| Google News RSS | recency layer; GDELT DOC API is excluded from the editorial cascade to keep the label channel and the evidence channel information-theoretically isolated | |
| Earnings | SEC EDGAR 8-K filings | tagged source_type: "filing", asymmetric pre-event-only filter |
| Finnhub company news | finance-first, ticker-keyed | |
| yfinance news | most-recent ~10 per ticker | |
| Google News RSS | backfill | |
| GDELT DOC API | multilingual long tail |
The quality filter is the single acceptance gate; FDs that fail any rule are written to forecasts_dropped.jsonl with a per-FD drop reason for the diagnostic report. The Comply/Surprise binary primary target (§3.2) is computed earlier, at the prior-state annotation stage, by scripts/annotate_prior_state.py; the script consumes the domain-specific prior-state oracle defined in Table 1 and writes both the partition tag (fd_type) and the binary label onto every FD before the quality filter sees it.
v2.1 ships per-benchmark retrieval routing rather than a single dense-cosine path:
all-mpnet-base-v2) cosine over the unified pool; per-source embedding_threshold, keyword-overlap floor, and lookback-window filter applied before the top-$K$ cut.actor_match_required) so only articles mentioning at least one of the FD's two countries are scored.scripts/link_earnings_articles.py); SBERT is bypassed entirely for this slice. Empirically, generic dense cosine over a heterogeneous news pool is the wrong default for a slice with a clean structured key, and the ticker-date join fills $\sim 90\%$ of FDs at $K=10$ where cosine left a long tail empty.
As of v2.2 (commit a373e89, 2026-04-23), the default embedder for both compute_relevance.py and scripts/etd_dedup.py is OpenAI Batch (text-embedding-3-small, native dimension $1536$), submitted via the OpenAI Batch API. This eliminates the GPU dependency from the entire build path and runs at a cost of $\sim \$0.30$ per full v2.1 rebuild. Local SBERT (all-mpnet-base-v2, dim $768$) remains available behind --embedder sbert as the offline / no-network fallback. The two backends maintain parallel caches (article_embeddings.npy for SBERT, article_embeddings_openai.npy for OpenAI) so backend swaps do not invalidate either; the resulting embedding_backend is treated as part of the cutoff identity (recorded in the manifest), and we do not mix backends within a published cutoff folder.
Every published benchmark/data/{cutoff}/ folder ships:
forecasts.jsonl, articles.jsonl: the two primary deliverables.benchmark.yaml: the effective build config; pasting it into configs/ and re-running the orchestrator reproduces the same deliverable modulo external API non-determinism.build_manifest.json: provenance record. Pins the exact git_sha, the model cutoff, the cutoff-buffer days, the per-benchmark FD counts, the article count, the active quality thresholds, and (in v2.2) the active embedder backend.checksums.sha256: SHA-256 over the two JSONL files, so any consumer can detect silent corruption between download and use.
Audit material (drop-reason reports, EDA HTML, per-stage staging snapshots) is routed to benchmark/audit/{cutoff}/ and is never mixed into the deliverable folder. The git_sha + benchmark.yaml pair is the complete reproduction recipe.
The gold subset (§5.1.1) is produced by scripts/build_gold_subset.py, which cascades the published v2.1 bundle through nine filters and one stratified sampling step. Every threshold is recorded in the gold folder's build_manifest.json, and a human-readable copy is mirrored into selection_criteria.md next to the data.
The cascade applies the rules below in order; the first failure drops the FD.
fd_type inclusion. Keep only FDs with $\text{fd\_type} \in \{\text{stability}, \text{change}\}$; drop unknown by default (override with --keep-unknown).GEOPOLITICALLY_SIGNIFICANT_ACTORS (G20 + NATO + Middle-East principals + East Asia powers; $\sim 70$ ISO-3 codes).
After the cascade, the surviving FDs are passed through a stratified sampler that hits per-(benchmark, fd_type) targets with deterministic seed. The default targets are: ForecastBench $60$ stability + $40$ change, GDELT-CAMEO $100 + 100$, Earnings $60 + 60$ (total $\leq 420$ FDs). When a stratum has fewer surviving FDs than its target, the sampler takes all of them; the realized stratum sizes are written to meta/distribution.md.
The gold folder is designed to stand alone: a consumer can download just benchmark/data/{cutoff}-gold/ and use it without any other file from the parent repo. In addition to the v2.1 deliverables (forecasts.jsonl, articles.jsonl, benchmark.yaml, build_manifest.json, checksums.sha256) it ships:
schema/forecast_dossier.schema.json + article.schema.json: full inline JSON Schema (Draft 2020-12, no $ref across files) plus a plain-English FIELD_REFERENCE.md.examples/load.py, validate.py, eval_template.py, usage.md: a stdlib-only loader, an SHA + schema validator, a pick-only baseline-runner skeleton with no EMR-ACH imports, and a five-query usage cookbook.selection_criteria.md: a human-readable copy of the cascade above, with the exact thresholds used.meta/selection_audit.json, distribution.md, parent_manifest_sha256.txt: per-FD why-kept audit, source / topic / horizon / fd_type breakdown, and the parent forecasts.jsonl SHA-256 so consumers can verify the lineage.LICENSE (MIT) + CITATION.cff.
The pipeline ships an optional Evidence-as-Time-stamped-Data (ETD) layer that decomposes raw articles into atomic, individually-verifiable facts. ETD is purely additive: the v2.1 baselines B1-B9 in §5.2 still consume raw articles; the ETD layer is wired into the planned hybrid baseline B10 and the facts-only baseline B10b in docs/V2_2_REFACTOR_BACKLOG.md (Category F). A worked production-filter verdict that illustrates how an extracted fact is dropped by the source-blocklist rule is in Appendix G.6.
scripts/articles_to_facts.py calls gpt-4o-mini per article with the v3 prompt, which requires (a) an explicit anchor table mapping each fact to the article paragraph it came from, (b) a verbatim quoted span from the article body for every fact, and (c) ISO-TimeML temporal anchors. Two structural validators run on every extraction: --strict-dates rejects facts with a publication-date / event-date mismatch, and --strict-quotes (Strategy 3, commit 9cbe9a1) rejects facts whose quoted span does not appear verbatim in the article. The prompt has gone through three revisions (v1 $\to$ v3): see §E.4 for the verifier-baseline trajectory.
scripts/etd_dedup.py embeds facts (default backend: OpenAI Batch text-embedding-3-small, fallback SBERT) and clusters by cosine $\geq \tau$ within a per-FD scope. Each cluster reduces to one canonical fact-id while retaining provenance pointers to all source articles. Cost is $\sim \$0.04$ per full v2.1 ETD pass.
An inverted index from canonical fact-ids to FD-ids is built from the article-id $\to$ fd-id map already on every FD (article_ids field). A baseline can then consume facts in two modes: facts-only (B10b: each FD's evidence pool replaced with its linked facts) or hybrid (B10: facts appended to the article pool with explicit provenance markers).
Two outlets, news.fjsen.com and world.people.com.cn, were identified as systematic sources of stale-republish content and are excluded at extraction time via articles_to_facts.py --source-blocklist. The Phase B verifier (a downstream LLM-as-judge that checks every extracted fact against the source article and rates support strength) reports a clean trajectory across prompt revisions: v1 baseline $15.5\%$ unsupported-at-high-confidence (the worst offender), v3 with anchor table + verbatim quote requirement $11.8\%$, and v3 + source blocklist $\sim 0\%$ (the residual stale-republish failures were the dominant remaining error mode).
This appendix expands the one-line descriptions in §5.2 with a short paragraph per baseline. The authoritative per-method reference, with prompt paths, config knobs, and known limitations, is benchmark/evaluation/BASELINES.md; the text below paraphrases it for the reader who does not want to leave the paper. Every baseline shares the same gpt-4o-mini-2024-07-18 backbone, the same retrieved article set ($n = 10$ after horizon filter), the same JSON pick contract ({"prediction": "<one of hypothesis_set>", "reasoning": "..."}), and the same prior-state expectation block that tells the model the status-quo outcome before asking it to pick Comply or Surprise.
A trivial baseline that always predicts the most-frequent class in the benchmark, disregarding both question and articles. It is not an LLM at all; it is the persistence-prior floor. On ForecastBench under the binary Comply/Surprise target the accuracy is the Comply-class rate, $\sim 83\%$ by construction; on GDELT-CAMEO and Earnings the rate is pending the Phase-3 build manifest. The paper treats any system that fails to exceed this floor on a given benchmark as having no measurable selection skill on that benchmark. The reference replaces the deprecated B8 (Verbalized Confidence) in every headline results table.
(model, temperature) configurations, plurality vote; default is temperature-only diversity ($T \in \{0.0, 0.5, 1.0\}$) at the same model. Controls for model-ensembling; cross-model heterogeneity is omitted for cost and is noted as an extension.docs/V2_2_REFACTOR_BACKLOG.md). Consume the ETD atomic-fact layer (Appendix E) alongside or in place of raw articles; the marginal value of the fact layer is the subject of Table 6.B4 through B9 collectively target three orthogonal alternative hypotheses for the source of EMR-ACH's lift: sampling-variance reduction (B4), generic multi-agent deliberation without a hypothesis matrix (B5, B6, B7), and model-ensembling (B9). If the full EMR-ACH system still outperforms after controlling for all three, the remaining gap is attributable to the evidence-matrix structure itself.
This appendix shows one concrete FD per benchmark, one worked dense-retrieval example, one worked earnings relational-join example, and one worked production-filter verdict. Long article bodies and tangential JSON fields are elided; all numeric IDs are drawn from the v2.1 build (benchmark/data/2026-01-01/, manifest SHA pinned in build_manifest.json, commit 0df1957).
This is a stability FD: the crowd-implied prior ("No") matched the resolved outcome, so Comply is correct. A persistence predictor wins trivially; the FD is excluded from headline metrics and reported on the stability floor row.
KWT-TUR sat at Tension throughout the prior 30 days (stability = 1.0, 6 prior events all-Tension). The 2026-03-01 resolution was also Tension, so the FD is Comply / stability. Editorial articles (NYT, Guardian, Google News) are retrieved for this pair with the actor-pair pre-filter; the GDELT KG that produced the label is excluded from retrieval per §5.1.
MMM had Beat in three of the prior four quarters (mode = Beat). The reported Q1-2026 result was Meet, which breaks the Beat prior: primary target Surprise, fd_type change. This is the stratum where forecasting skill is actually tested; the model must read the pre-event article pool and detect the miss signal against a chronic-beater prior. Note the ten article_ids: all ten slots are filled by the ticker-date relational join described in §G.5, not by dense cosine.
For a ForecastBench or GDELT-CAMEO FD, scripts/compute_relevance.py runs the following per-FD flow (simplified; full mechanics in Appendix C.4):
publish_date < forecast_point and within $T$ days lookback. For GDELT-CAMEO apply the actor-pair pre-filter: drop articles whose text mentions neither the source nor the object country (ISO-3 or demonym match). At this point the candidate pool for a typical GDELT-CAMEO FD is on the order of a few hundred editorial articles.text-embedding-3-small (dim 1536) via Batch; SBERT all-mpnet-base-v2 (dim 768) is the offline fallback. The two caches coexist and the active one is pinned in build_manifest.json.embedding_threshold floor and the keyword-overlap floor. Survivors are ordered by score.article_ids slot. At experiment time the runner's apply_experiment_horizon() drops any survivor with publish_date > resolution_date - horizon_days (default 14) to enforce the forecast embargo; the pool feeding the EMR-ACH matrix $A$ is whatever remains after that filter.
For the GDELT-CAMEO FD in §G.2, the five surviving articles after the horizon filter (reported date $\leq 2026\text{-}02\text{-}15$) are the ones enumerated in article_ids. EMR-ACH then scores each of these against $m = 9$ contrastive indicators (Peace-vs-Tension, Tension-vs-Violence, Peace-vs-Violence, three per pair) and aggregates under $d_j$ weights into three per-hypothesis scores whose argmax is the final pick.
scripts/link_earnings_articles.py does not call SBERT or OpenAI embeddings. For each earnings FD it runs a structured key join:
ticker, announce_date, lookback=90, $K = 10$.tickers contains the FD ticker and publish_date $\in$ [announce_date - lookback, announce_date).The MMM / 2026-01-20 FD in §G.3 has all ten slots filled because 3M has a well-populated Q1-2026 pre-event news window across SEC filings, Finnhub, and yfinance. Dense cosine over a generic editorial pool was empirically the wrong default here: the structured key is already unambiguous, so cosine re-ranking adds noise. This is why the v2.1 routing (§C.4) picks the relational join for the earnings slice and dense cosine for the other two benchmarks.
The production filter for the ETD atomic-fact layer (§E.1) composes several drop rules; a worked verdict looks like:
news.fjsen.com is in the stale-republish blocklist (§E.4).
Under the v1 prompt the same fact would have survived with a high-confidence rating despite the stale-republish source; the v3 prompt plus source blocklist is what drops the $\sim 15\%$ unsupported-at-high-confidence tail to $\sim 0\%$ (§E.4). Facts that survive every rule propagate to Stage 2 (dedup) and Stage 3 (FD linkage); dropped facts are written to etd_dropped.jsonl with the rule name as the drop reason, mirroring the forecasts-level audit trail.